Welcome to the eighth installment of a new series of NSX troubleshooting scenarios. Thanks to everyone who took the time to comment on the first half of scenario eight. Today I’ll be performing some troubleshooting and will show how I came to the solution.
Please see the first half for more detail on the problem symptoms and some scoping.
Getting Started
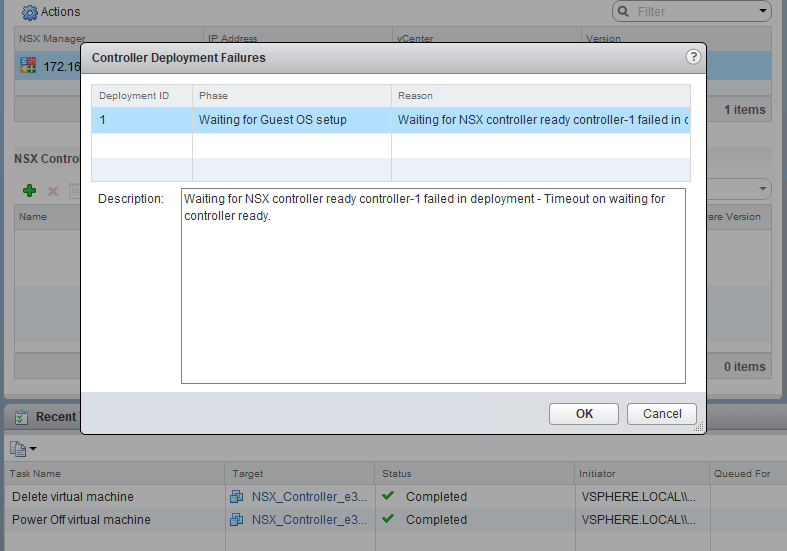
In the first half of scenario 8, we saw that our fictional administrator was getting an error message while trying to deploy the first of three controller nodes.
The exact error was:
“Waiting for NSX controller ready controller-1 failed in deployment – Timeout on waiting for controller ready.”
Unfortunately, this doesn’t tell us a whole lot aside from the fact that the manager was waiting and eventually gave up.
Now, before we begin troubleshooting, we should first think about the normal process for controller deployment. What exactly happens behind the scenes?
- The necessary inputs are provided via the vSphere Client or REST API (i.e. deployment information like datastore, IP Pool etc).
- NSX Manager then deploys a controller OVF template that is stored on it’s local filesystem. It does this using vSphere API calls via its inventory tie-in with vCenter Server.
- Once the OVF template is deployed, it will be powered on.
- During initial power on, the machine will receive an IP address, either via DHCP or via the pool assignment.
- Once the controller node has booted, NSX Manager will begin to push the necessary configuration information to it via REST API calls.
- Once the controller node is up, and is able to serve requests and communicate with NSX Manager, the deployment is considered successful and the status in the UI changes from ‘Deploying’ to ‘Connected’
Let’s have a look at the NSX Manager logging to see if we can get more information:
2018-04-29 22:13:27.951 GMT ERROR taskScheduler-28 ControllerPoweronAdvisor:158 - failed in connecting to controller node 172.16.15.43 org.springframework.web.client.ResourceAccessException: I/O error on POST request for "https://172.16.15.43:443/ws.v1/login": No route to host (Host unreachable); nested exception is java.net.NoRouteToHostException: No route to host (Host unreachable)
As you can see above, NSX Manager is attempting to communicate with the controller using a REST POST call, and it’s failing. The reason, however, gives us more than the UI – No route to host. It seems clear that there is some kind of a L2/L3 network communication problem between NSX Manager and our newly deployed controller.
Digging In
Although our controller reports as ‘Deploying’ in the UI, we still have a window of opportunity before the appliance is deleted. It appears that NSX Manager gives the controller node about 10 minutes before it gives up and the deployment is rolled back. In this time, we can log in and do some basic network connectivity tests.
First, I was able to confirm that the appliance does have an IP address from the pool and that the gateway was configured.


Second, I attempted to ping the NSX Manager appliance in the 172.16.1.0/24 network. Not surprisingly, it cannot be reached.
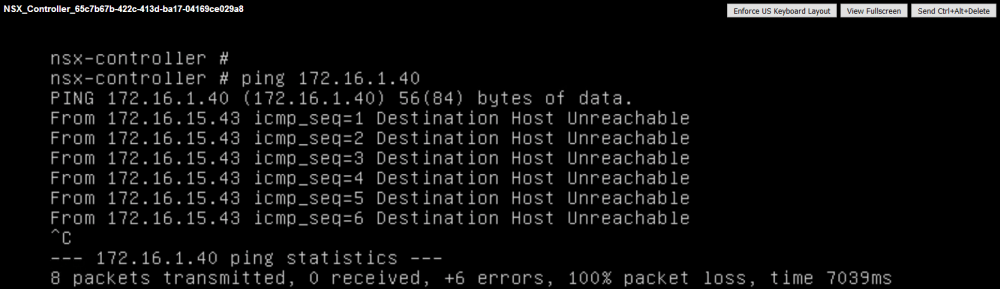
Narrowing things down even more, I can see that the default gateway of 172.16.15.1 can’t be reached either.
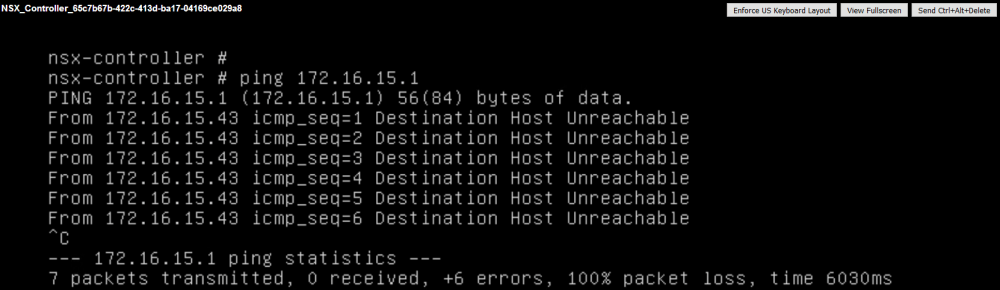
This appliance will not be able to communicate outside of its subnet. If the controller node can’t communicate with NSX Manager to service the necessary API calls, manager will assume the deployment has failed and the deployment is rolled back.
Fixing the Problem
Although it’s common to have NSX Manager and the Control Cluster in the same subnet, there is no reason they can’t be multiple hops away. In this case, we couldn’t access 172.16.15.1, which is supposed to be a L3 switch SVI. Not only could we not reach this from the controller node, but not from anywhere else in the network either.
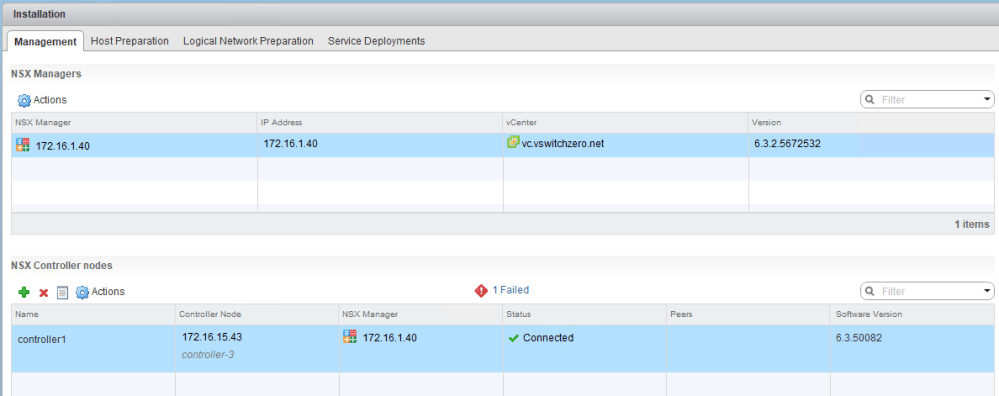
That said, we consulted with the local network administrator and discovered that the controllers were in VLAN 15, and that an SVI had not yet been configured for that VLAN. The default gateway address of 172.16.15.1 simply didn’t exist. Once VLAN 15 had a virtual routing interface configured, subsequent controller deployments were successful!
From the switch routing table after the SVI was added:
SSH@tx24#sh ip route Total number of IP routes: 5, avail: 12281 (out of max 12286) B:BGP D:Connected R:RIP S:Static O:OSPF *:Candidate default Destination NetMask Gateway Port Cost Type 0.0.0.0 0.0.0.0 172.16.1.12 v1 1 S 1 172.16.1.0 255.255.255.0 0.0.0.0 v1 1 D 2 172.16.11.0 255.255.255.0 0.0.0.0 v11 1 D 3 172.16.15.0 255.255.255.0 0.0.0.0 v15 1 D 4 172.16.76.0 255.255.255.0 0.0.0.0 v76 1 D
Now the controller is listed as ‘Connected’ instead of ‘Deploying’:
Reader Comments
I wanted to take a moment to share a couple of twitter comments I received on the first half of this scenario. @alagoutte correctly points out that NSX Manager and the controller node aren’t in the same subnet and that there may be communication problems:
Also, @nmorgowicz hit the nail on the head:
Thanks to everyone who took the time to post.
Conclusion
As always, if you get a vague message in the UI, don’t hesitate to look at the logging for more detail. Quite often the problem will become clear with the extra detail provided there. I hope this was useful. Please keep the troubleshooting scenario suggestions coming!
Please feel free to leave a comment below or reach out to me on Twitter (@vswitchzero)

Great series, hope to see more. I’ve just used your Scenario 2 article to eventually resolve a problem with one host in a cluster which was not being prepared. Many thanks!
This is an awesome series! I really like how you methodically go through the troubleshooting steps and include a lot of technical detail on how it all works. Highly recommended for anyone managing NSX. Thanks!
Thank you for this series. It is very helpful to find ways to approach troubleshooting various NSX issues I may encounter.
Thanks for the detailed write-up about the Controller deployment.
Good one Mike
Thank you for that series a few of those actually I just experienced with my new customer so you saved lots of my time !
It nice series
Thanks for creating this series, it’s a great resource for the community!
Great Article!
guys i am not using any Vlans or routing Protocol Everything is on same range ip my controller deploy but when its give error so its disapear give me this message guys someone help ?
i tried alot but not working its been 2 weeks kindly who have a solution