Last week, I discussed the manual deployment of NSX-T controller nodes. Today, I’ll take a look at adding standalone ESXi hosts.
Although people usually associate manual deployment with KVM hypervisors, there is no reason you can’t do the same with ESXi hosts. Obviously, automating this process with vCenter Server as a compute manager has its advantages, but one of the empowering features of NSX-T is that is has no dependency on vCenter Server whatsoever.
Obtaining the ESXi VIBs
First, we’ll need to download the ESXi host VIBs. In my case, the hosts are running ESXi 6.5 U2, so I downloaded the correct 6.5 VIBs from the NSX-T download site.
Once I had obtained the ZIP file, I used WinSCP to copy it to the /tmp location on my ESXi host. The file is only a few megabytes in size so it can go just about anywhere. If you’ve got a lot of hosts to do, putting it in a shared datastore makes sense.
Installing the ESXi VIBs
Because the NSX-T kernel module is comprised of a number of VIBs, we need to install it as an ‘offline depot’ as opposed to individual VIB files. That said, there is no need to extract the ZIP file. To install it, I used the esxcli software vib install command as shown below:
[root@esx-a3:/tmp] esxcli software vib install --depot=/tmp/nsx-lcp-2.3.1.0.0.11294289-esx65.zip
Installation Result
Message: Operation finished successfully.
Reboot Required: false
VIBs Installed: VMware_bootbank_epsec-mux_6.5.0esx65-9272189, VMware_bootbank_nsx-aggservice_2.3.1.0.0-6.5.11294539, VMware_bootbank_nsx-cli-libs_2.3.1.0.0-6.5.11294490, VMware_bootbank_nsx-common-libs_2.3.1.0.0-6.5.11294490, VMware_bootbank_nsx-da_2.3.1.0.0-6.5.11294539, VMware_bootbank_nsx-esx-datapath_2.3.1.0.0-6.5.11294337, VMware_bootbank_nsx-exporter_2.3.1.0.0-6.5.11294539, VMware_bootbank_nsx-host_2.3.1.0.0-6.5.11294289, VMware_bootbank_nsx-metrics-libs_2.3.1.0.0-6.5.11294490, VMware_bootbank_nsx-mpa_2.3.1.0.0-6.5.11294539, VMware_bootbank_nsx-nestdb-libs_2.3.1.0.0-6.5.11294490, VMware_bootbank_nsx-nestdb_2.3.1.0.0-6.5.11294421, VMware_bootbank_nsx-netcpa_2.3.1.0.0-6.5.11294485, VMware_bootbank_nsx-opsagent_2.3.1.0.0-6.5.11294539, VMware_bootbank_nsx-platform-client_2.3.1.0.0-6.5.11294539, VMware_bootbank_nsx-profiling-libs_2.3.1.0.0-6.5.11294490, VMware_bootbank_nsx-proxy_2.3.1.0.0-6.5.11294520, VMware_bootbank_nsx-python-gevent_1.1.0-9273114, VMware_bootbank_nsx-python-greenlet_0.4.9-9272996, VMware_bootbank_nsx-python-logging_2.3.1.0.0-6.5.11294409, VMware_bootbank_nsx-python-protobuf_2.6.1-9273048, VMware_bootbank_nsx-rpc-libs_2.3.1.0.0-6.5.11294490, VMware_bootbank_nsx-sfhc_2.3.1.0.0-6.5.11294539, VMware_bootbank_nsx-shared-libs_2.3.0.0.0-6.5.10474844, VMware_bootbank_nsxcli_2.3.1.0.0-6.5.11294343
VIBs Removed:
VIBs Skipped:
Remember, your host will need to be in maintenance mode for the installation to succeed. Once finished, a total of 24 new VIBs were installed as shown:
[root@esx-a3:/tmp] esxcli software vib list |grep -i nsx
nsx-aggservice 2.3.1.0.0-6.5.11294539 VMware VMwareCertified 2019-02-15
nsx-cli-libs 2.3.1.0.0-6.5.11294490 VMware VMwareCertified 2019-02-15
nsx-common-libs 2.3.1.0.0-6.5.11294490 VMware VMwareCertified 2019-02-15
nsx-da 2.3.1.0.0-6.5.11294539 VMware VMwareCertified 2019-02-15
nsx-esx-datapath 2.3.1.0.0-6.5.11294337 VMware VMwareCertified 2019-02-15
nsx-exporter 2.3.1.0.0-6.5.11294539 VMware VMwareCertified 2019-02-15
nsx-host 2.3.1.0.0-6.5.11294289 VMware VMwareCertified 2019-02-15
nsx-metrics-libs 2.3.1.0.0-6.5.11294490 VMware VMwareCertified 2019-02-15
nsx-mpa 2.3.1.0.0-6.5.11294539 VMware VMwareCertified 2019-02-15
nsx-nestdb-libs 2.3.1.0.0-6.5.11294490 VMware VMwareCertified 2019-02-15
nsx-nestdb 2.3.1.0.0-6.5.11294421 VMware VMwareCertified 2019-02-15
nsx-netcpa 2.3.1.0.0-6.5.11294485 VMware VMwareCertified 2019-02-15
nsx-opsagent 2.3.1.0.0-6.5.11294539 VMware VMwareCertified 2019-02-15
nsx-platform-client 2.3.1.0.0-6.5.11294539 VMware VMwareCertified 2019-02-15
nsx-profiling-libs 2.3.1.0.0-6.5.11294490 VMware VMwareCertified 2019-02-15
nsx-proxy 2.3.1.0.0-6.5.11294520 VMware VMwareCertified 2019-02-15
nsx-python-gevent 1.1.0-9273114 VMware VMwareCertified 2019-02-15
nsx-python-greenlet 0.4.9-9272996 VMware VMwareCertified 2019-02-15
nsx-python-logging 2.3.1.0.0-6.5.11294409 VMware VMwareCertified 2019-02-15
nsx-python-protobuf 2.6.1-9273048 VMware VMwareCertified 2019-02-15
nsx-rpc-libs 2.3.1.0.0-6.5.11294490 VMware VMwareCertified 2019-02-15
nsx-sfhc 2.3.1.0.0-6.5.11294539 VMware VMwareCertified 2019-02-15
nsx-shared-libs 2.3.0.0.0-6.5.10474844 VMware VMwareCertified 2019-02-15
nsxcli 2.3.1.0.0-6.5.11294343 VMware VMwareCertified 2019-02-15
You can find information on the purpose of some of these VIBs in the NSX-T documentation.
Connecting the ESXi Host to the Management Plane
Now that we have the required software installed, we need to connect the ESXi host to NSX Manager. To begin, we’ll need to get the certificate thumbprint from the NSX Manager:
nsxmanager> get certificate api thumbprint
ccdbda93573cd1dbec386b620db52d5275c4a76a5120087a174d00d4508c1493
Next, we need to drop into the nsxcli shell from the ESXi CLI prompt, and then run the join management-plane command as shown below:
[root@esx-a3] # nsxcli
esx-a3> join management-plane 172.16.1.40 username admin thumbprint ccdbda93573cd1dbec386b620db52d5275c4a76a5120087a174d00d4508c1493
Password for API user: ********
Node successfully registered as Fabric Node: 0b08c694-3155-11e9-8a6c-0f1235732823
If all went well, we should now see our NSX Manager listed as connected:
esx-a3> get managers
- 172.16.1.40 Connected
From the root prompt of the ESXi host, we can see that there are now established TCP connections to the NSX Manager appliance on the RabbitMQ port 5671.
[root@esx-a3:/tmp] esxcli network ip connection list |grep 5671
tcp 0 0 172.16.1.23:55477 172.16.1.40:5671 ESTABLISHED 84232 newreno mpa
tcp 0 0 172.16.1.23:36956 172.16.1.40:5671 ESTABLISHED 84232 newreno mpa
From the NSX UI, we can now see the host appear as connected under ‘Standalone Hosts’:
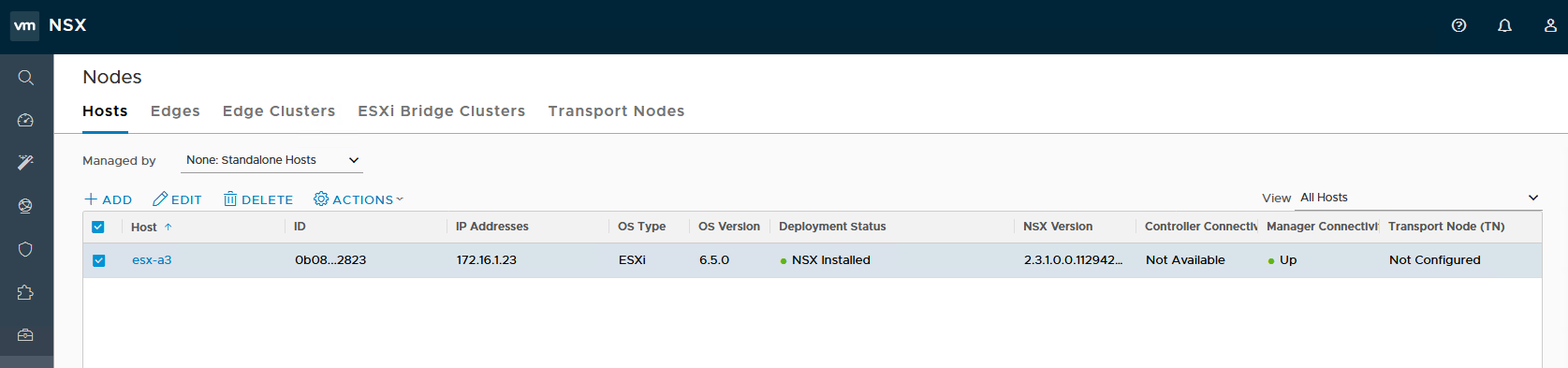
As a next step, you’ll want to add this new host as a transport node and you should be good to go.
It’s great to have the flexibility to do this completely without the assistance of vCenter Server. Anyone who has had to deal with the quirks of VC integration and ESX Agent Manager (EAM) in NSX-V will certainly appreciate this.