A few years back, VMware implemented a password expiry policy of 90 days for the root account on the vCenter Server appliance. Although this account isn’t used much once vCenter is up and running, you do require it for VAMI access or to login via SSH. Administrators frequently use the VAMI for vCenter upgrades, so you will inevitably run into this problem sooner or later.

In vCenter Server 7.x the error message you receive will be:
Exception in invoking authentication handler User password expired.
For those not familiar with the CLI access options in vCenter Server, you may head over to the “Users and Groups” section in the vSphere client to look at “localos” domain accounts where root is located. You won’t be able to manipulate this account from the vSphere Client and the account will not be listed as “locked” or “disabled”.
Thankfully, resetting your password is a piece of cake via CLI. SSH should be enabled by default for your vCenter Server. Simply login using your favorite SSH client and you’ll be greeted by a password change prompt:
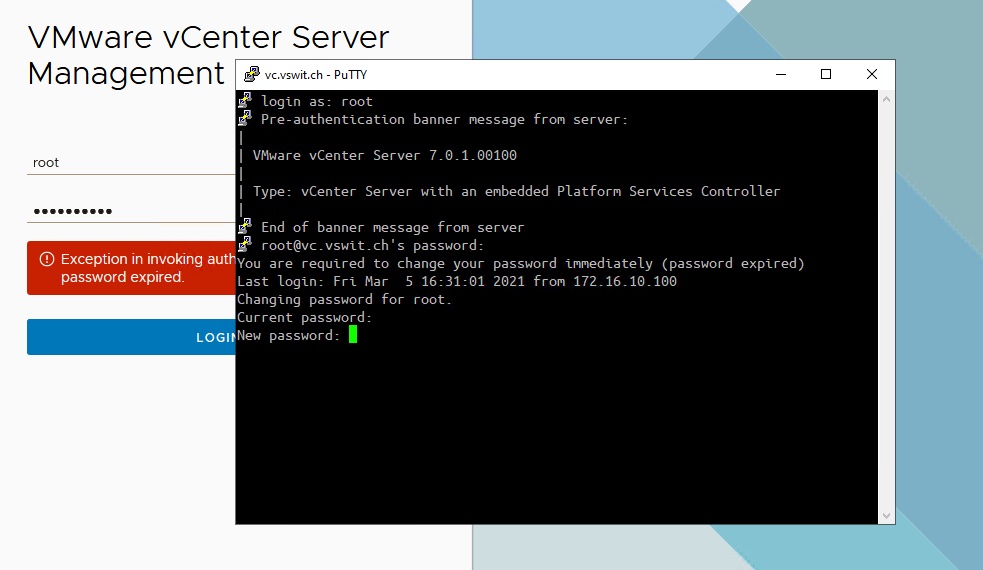
Changing your password may be an exercise in frustration as this prompt will prevent you from using similar passwords and enforce some complexity requirements (see how to get around this below). Once you’ve changed the password, you’ll be able to login to the vCenter Management Interface (VAMI) again.
If this is an isolated lab environment – don’t do this in production – and you don’t want to change your password, you can set a temporary password and then change it back via the root shell as follows:
Command> shell
Shell access is granted to root
root@vc [ ~ ]# passwd
New password:
Retype new password:
passwd: password updated successfully
root@vc [ ~ ]#
Verify how long you’ve got till your password expires again by using the chage command:
root@vc [ ~ ]# chage -l root
Last password change : Mar 05, 2021
Password expires : Jun 03, 2021
Password inactive : never
Account expires : never
Minimum number of days between password change : 0
Maximum number of days between password change : 90
Number of days of warning before password expires : 7
And there you have it. Hopefully you found this helpful.