Welcome to the first of what I hope to be many NSX troubleshooting posts. As someone who has been working in back-line support for many years, troubleshooting is really the bread and butter of what I do every day. Solving problems in vSphere can be challenging enough, but NSX adds another thick layer of complexity to wrap your head around.
I find that there is a lot of NSX documentation out there but most of it is on to how to configure NSX and how it works – not a whole lot on troubleshooting. What I hope to do in these posts is spark some conversation and share some of the common issues I run across from day to day. Each scenario will hopefully be a two-part post. The first will be an outline of the symptoms and problem statement along with bits of information from the environment. The second will be the solution, including the troubleshooting and investigation I did to get there. I hope to leave a gap of a few days between the problem and solution posts to give people some time to comment, ask questions and provide their thoughts on what the problem could be!
NSX Troubleshooting Scenario 1
As always, let’s start with a somewhat vague customer problem description:
“Help! I’ve deployed a new cluster (compute-b) and for some reason I can’t access internal web sites on the compute-a cluster or at any other internet site.”
Of course, this is really only a small description of what the customer believes the problem to be. One of the key tasks for anyone working in support is to scope the problem and put together an accurate problem statement. But before we begin, let’s have a look at the customer’s environment to better understand how the new compute-b cluster fits into the grand scheme of things.
Since we seem to be able to consistently reproduce the issue by using a VM called win-b1 accessing a web server called web-a1, we’ll focus on these machines for our troubleshooting.
From a high level, here is the topology of the NSX environment, including where these VMs sit:

An important thing to note is that both ESGs and the DLR control VM are sitting in the compute-a cluster. Both esg-a1 and esg-a2 are in ECMP mode. Any northbound or internet traffic would need to hit cluster compute-a before leaving the environment.
The underlay L2/L3 network looks similar to:
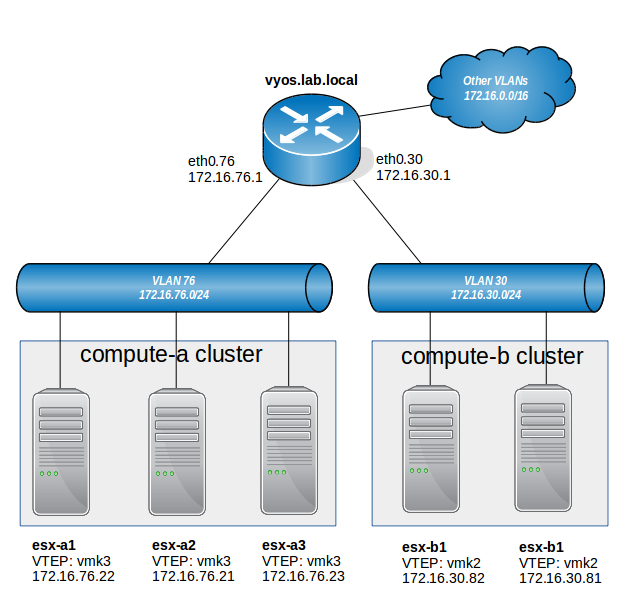
Of note here, we can see that the VXLAN VTEPs for the hosts in compute-a are in VLAN 76 and the VTEPs for compute-b are in VLAN 30. Routing between these segments is provided by a router called vyos.lab.local.
Next, let’s have a quick look at the NSX configuration. First, we can see that both clusters are prepped and have the VIBs installed:
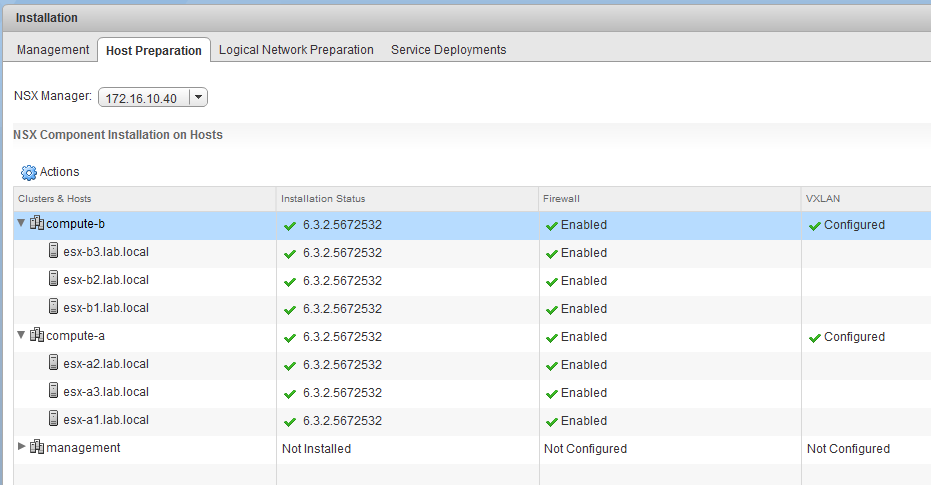
It should also be noted that the Distributed Firewall is enabled.
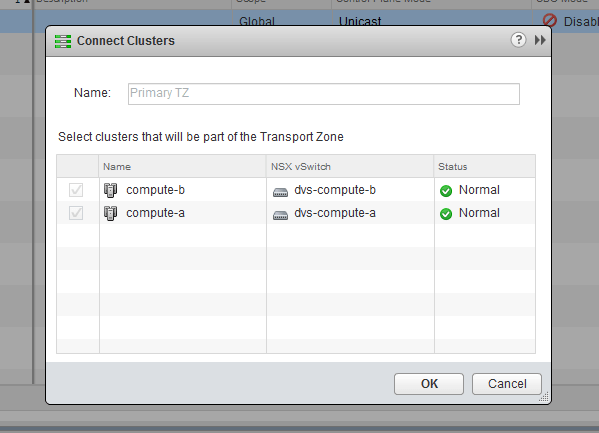
We can also see that the two clusters are both in the same Transport Zone, which means they’ll have access to the same Logical Switches. Take note also that each cluster has it’s own Distributed Switch.
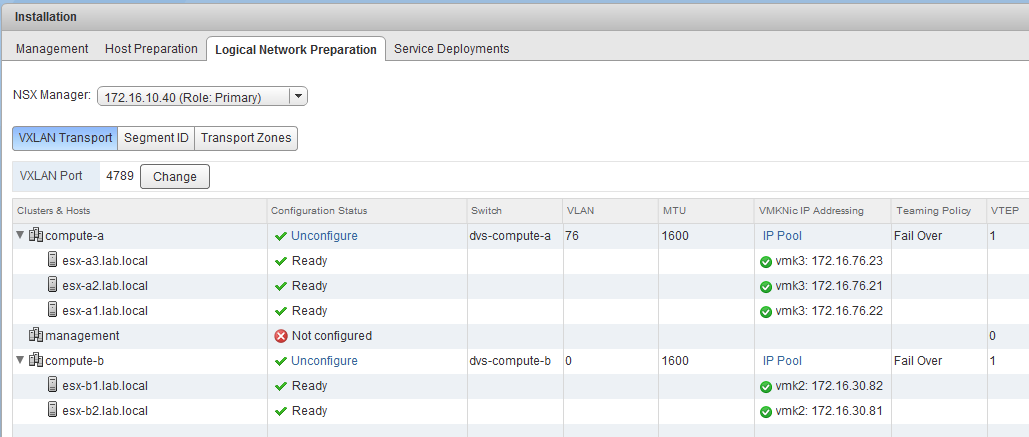
Below is a view of the VXLAN preparation. Take note that all hosts have VTEP IPs assigned and that compute-a and compute-b also have different Distributed Switches configured. Everything looks to be green. MTU is the default 1600, as expected.
The Logical Switch in question is called ‘Blue Network’ running in a Unicast replication mode. Both web-a1 and win-b1 are sitting on this wire.

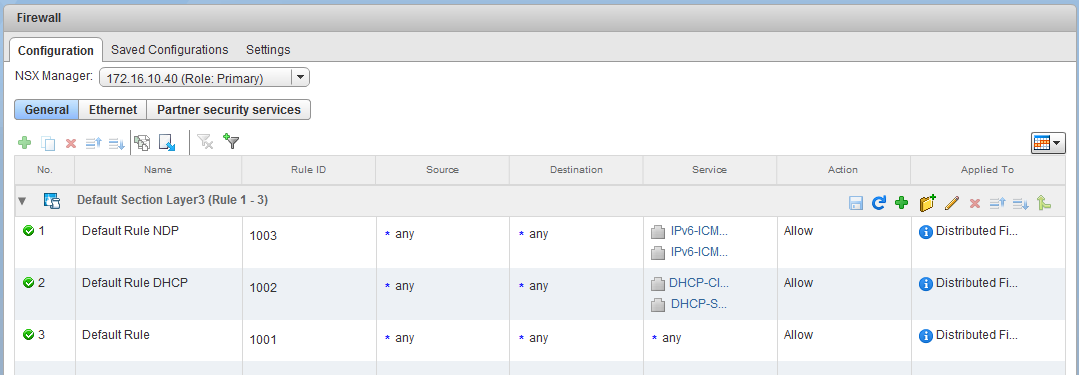
Although the Distributed Firewall is enabled on both clusters, it doesn’t appear that any custom rules have been defined. Only the default ‘allow’ rules exist in the default section.
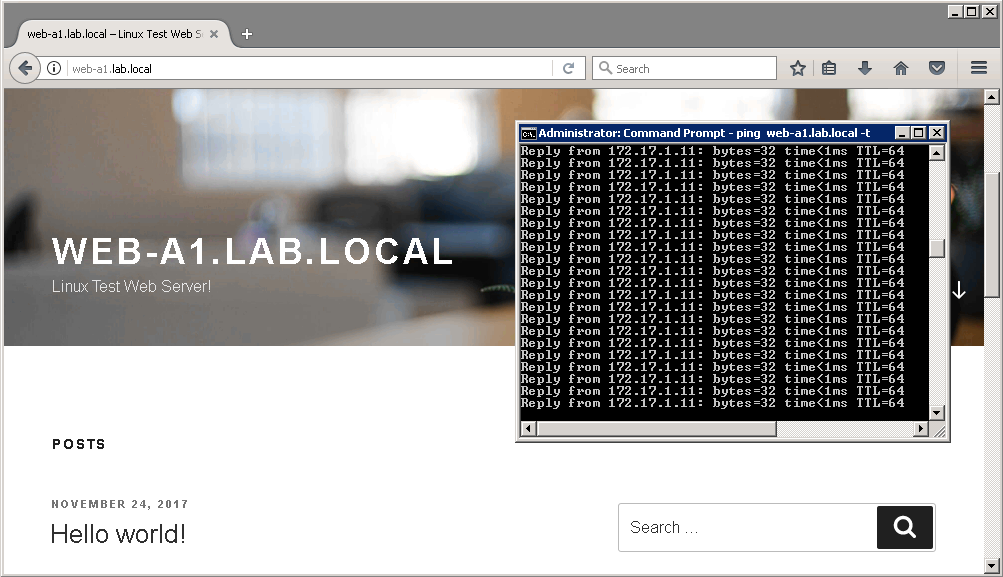
Below is what the web-a1’s landing page looks like from a VM in compute-a when it loads correctly:
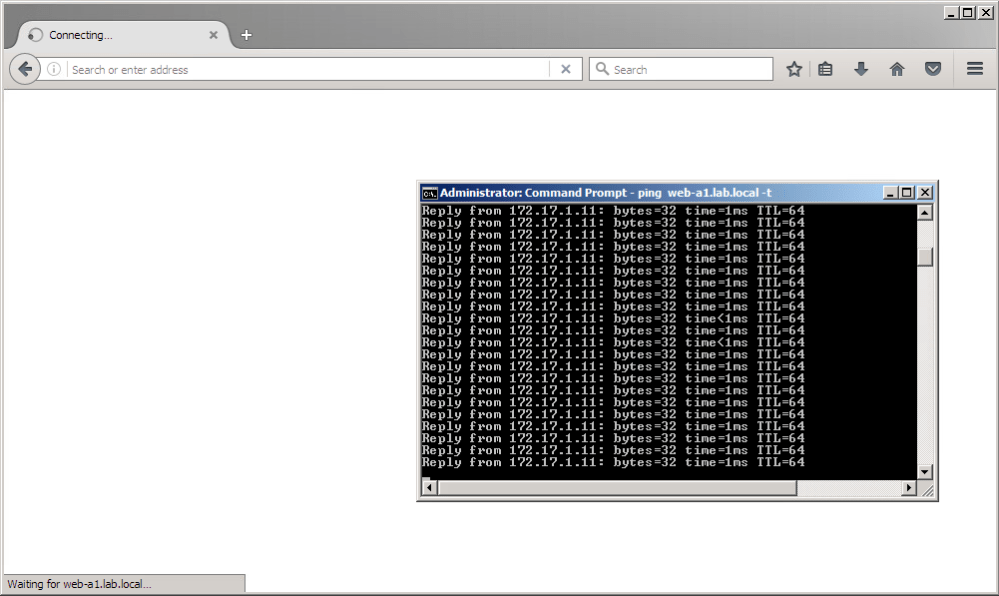
And when broken from win-b1 in compute-b:
So now that we’ve had a chance to see the environment and the problem for ourselves, let’s summarize some of the initial scoping done:
- All VMs on the logical switches can ping eachother, even between clusters. I.e. a VM in compute-a can ping a VM in compute-b and vice-versa.
- All VMs in compute-b can ping their DLR gateway address, and can get a DHCP address via DHCP relay without issue.
- All VMs in both clusters can ping northbound IPs without issue.
- All of the VMs in cluster compute-a can access the Apache web server linux-a1, which is also in compute-a. They can ping the web server and access it via browser.
- VMs in compute-b can ping the linux-a1 web server, but the landing page fails to load in a browser.
- VMs in compute-b can ping any northbound address, but when accessing external web sites, they will often fail to load in the same manner.
- DNS resolution appears to work just fine from both clusters.
Here are a few other verbal tidbits from the customer that may help:
- There are no physical firewalls between VLAN 76 and VLAN 30, or between any other internal VLANs.
- The DNS server and DHCP server are northbound in VLAN 10 (172.16.10.0/24).
- BGP is the routing protocol used between the DLR, ESGs and other northbound routers.
- The physical switches that hosts in compute-a and compute-b connect to have an MTU of 9000 set on all ports – higher than the minimum 1600 required.
So now that we’ve got a good problem statement and have done some initial scoping. It’s time to start digging in!
What’s Next?
Part 2 of this scenario is now live as of 12/5/2017! Please read on to see the solution as well as some troubleshooting techniques.
If you are interested, have a look through the information provided above and let me know what you would check or what you think the problem may be! I want to hear your suggestions!
What other information would you need to see? What tests would you run? What do you know is NOT the problem based on the information and observations here?
Please feel free to leave a comment below or via Twitter (@vswitchzero).

what a good idea ! i can’t wait to read the rest.