Welcome to the thirteenth installment of my NSX troubleshooting series. What I hope to do in these posts is share some of the common issues I run across from day to day. Each scenario will be a two-part post. The first will be an outline of the symptoms and problem statement along with bits of information from the environment. The second will be the solution, including the troubleshooting and investigation I did to get there.
The Scenario
As always, we’ll start with a brief problem statement:
“After recovering from a storage outage, we’re unable to re-deploy any of our missing DLRs and ESGs. Help!”
With this type of a problem description, the first order of business is to find out EXACTLY what happened. After a lengthy discussion with the fictional customer, we were able to piece together the following sequence of events:
- The SAN suffered a catastrophic failure.
- All of the LUNs were continuously replicated to another SAN over the years, so these replicated LUNs were presented to the hosts in the compute-a cluster.
- After a rescan, the VMFS volumes were re-signatured and the datastores and all files were again accessible.
- All of the VMs on those datastores were manually added back to the vCenter Inventory except the DLRs and ESGs.
- All DLRs and ESGs were deleted from the datastore so that they could be freshly re-deployed.
The customer did realize that in point number 5 above that any ESGs re-added to the inventory would no longer be valid because of mismatched UUIDs. Deleting these from disk and re-deploying was a good idea.
NSX is throwing many high and critical events because of the missing ESG and DLR appliances, as expected.
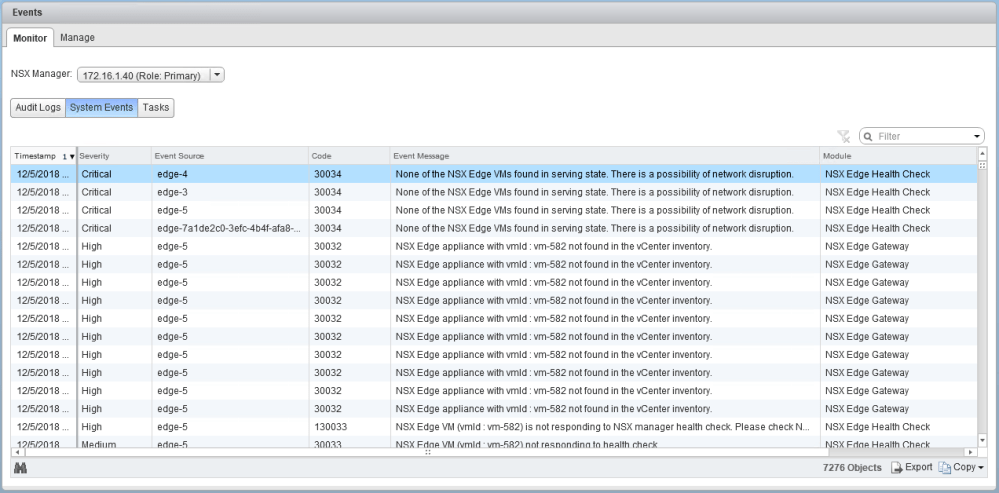
There are six appliances in total, including three DLRs and three ESGs.
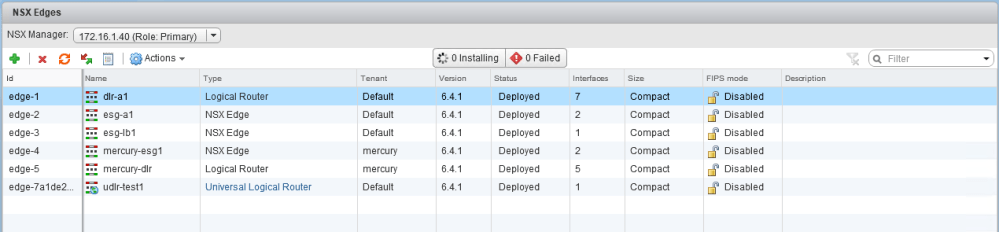
Oddly, all of them are reported as being ‘Deployed’ in the ‘NSX Edges’ view.
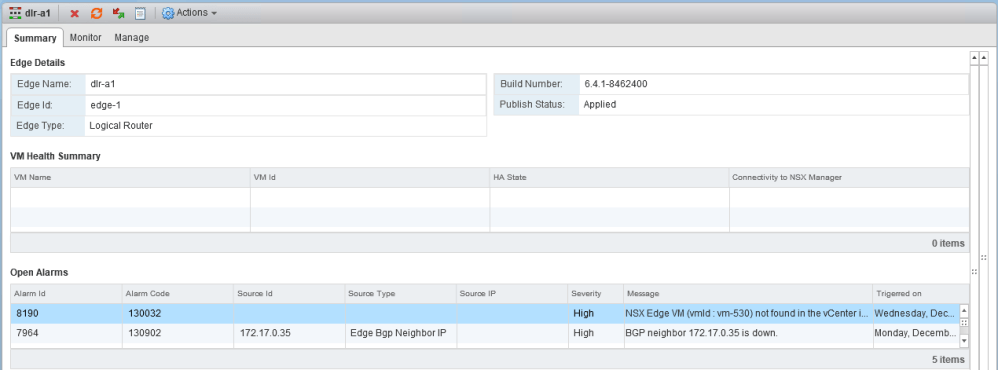
Looking at dlr-a1, we can see that there are no VMs listed in the health summary, and the latest open alarm reports that the moref vm-530 isn’t in the vCenter inventory.
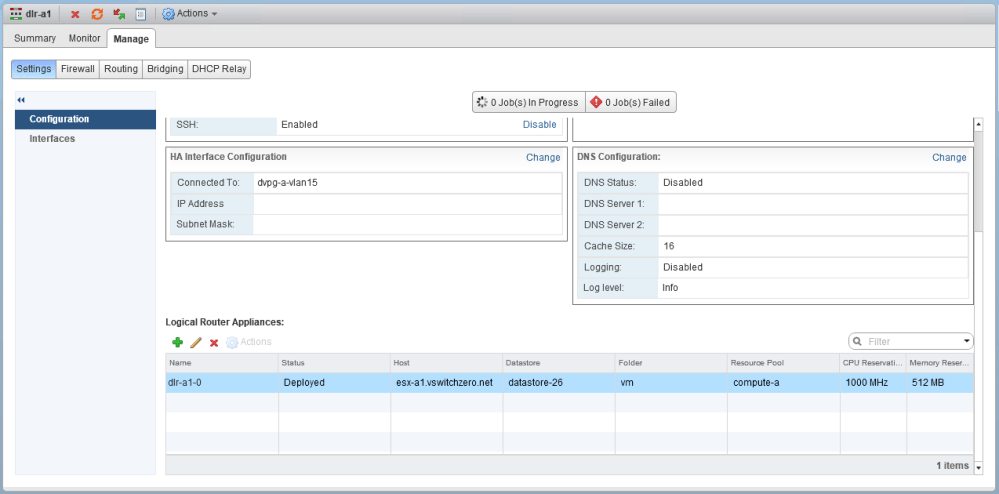
On the ‘Manage’ tab, under ‘Configuration’, we can see that the appliance still lists as deployed on host esx-a1 for some reason.
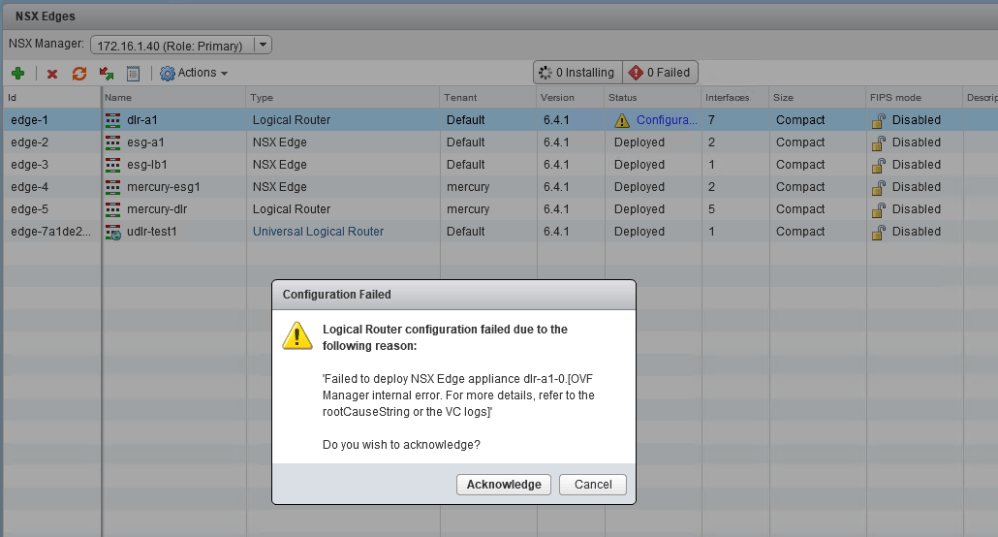
Attempting to redeploy the appliance always leads to the above error message. It fails to deploy. After taking a look in the vCenter Events, it doesn’t appear that deployment is even attempted. I.e. there are no tasks at all related to this deployment attempt.
What’s Next
I’ll post the solution in the next day or two, but how would you handle this scenario? Let me know! Please feel free to leave a comment below or via Twitter (@vswitchzero).
