If you are reading this post, you’ve probably already come to the realization that the ‘Tenant’ field for ESGs can’t be changed in the UI. Once the appliance is deployed, this string value appears set in stone.
Although it can’t be modified in the UI without creating a new appliance from scratch, it’s pretty easy to modify this field via REST API calls. After having come across a question on the VMware communities forum regarding this, I thought I’d write a quick post on the process.
Step 1: Retrieve the ESG/DLR Configuration
First, you’ll need to do a GET call to retrieve the current ESG/DLR configuration in XML format. I won’t cover the basics of REST API calls in this post as the topic is well covered elsewhere. If you’ve never done REST API calls before, I’d recommend doing some reading on the subject before proceeding.
I’ll be using the popular Postman utility for this. First, we’ll need to find the moref identifier of the ESG/DLR in question.
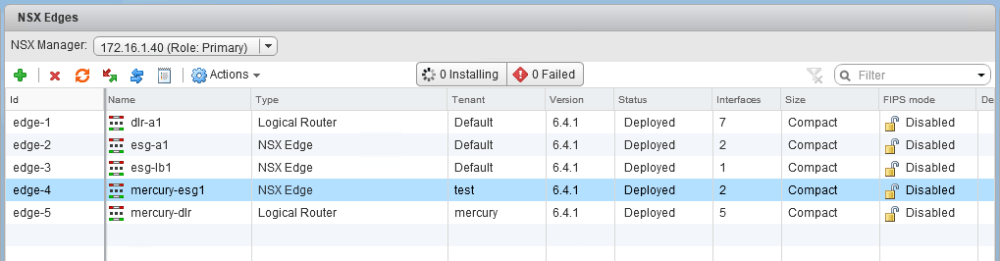
You can easily find this from the ‘Edges’ view in the UI. In my case, I want to modify the edge called mercury-esg1, which is edge-4. Notice that someone put the string ‘test’ in as the tenant, which we want to change to ‘mercury’.
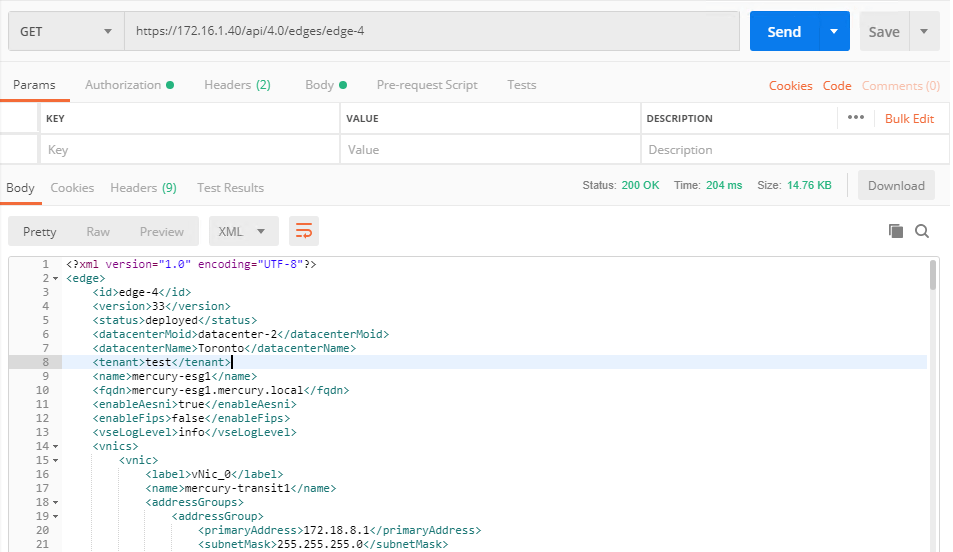
From Postman, we’ll run the following API call to retrieve edge-4’s configuration:
GET https://<nsxmgrip>/api/4.0/edges/edge-4
I got a 200 OK response, with all the config in XML format returned.
Step 2: Make the Necessary Changes
Next, I’ll copy and paste all the returned XML data into a text editor. The XML section for the tenant string is right near the top:
<edge>
<id>edge-4</id>
<version>32</version>
<status>deployed</status>
<datacenterMoid>datacenter-2</datacenterMoid>
<datacenterName>Toronto</datacenterName>
<tenant>test</tenant>
...
I will simply change <tenant>test</tenant> to <tenant>mercury</tenant>.
Step 3: Apply the Modified Configuration
The final step is to take your modified XML configuration data and apply it back to the ESG/DLR in question. This is as simple as changing your REST API call from GET to PUT and pasting the modified configuration into the ‘Body’ of the call.
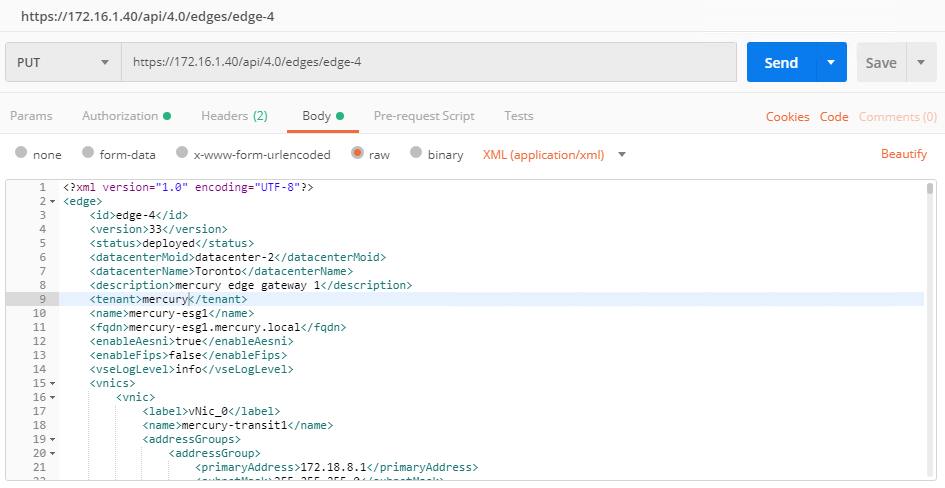
If your call was successful, you should get a 204 No Content response.
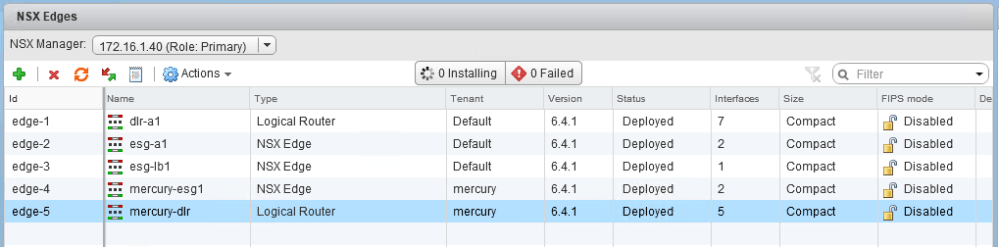
And there you have it – the tenant field has been updated. Unfortunately, I haven’t had any success updating the description field via API. The <description> tag appears to be ignored in this PUT call for some reason. If anyone has any success with this, please let me know.
PowerNSX Alternative
If you prefer using PowerNSX to API calls, the Set-NsxEdge cmdlet can also work. The cmdlet uses the same API calls behind the scene, but can be quicker to execute:
PS C:\Users\mike.VSWITCHZERO> $edge = get-nsxedge mercury-esg1 PS C:\Users\mike.VSWITCHZERO> $edge.tenant = "hello" PS C:\Users\mike.VSWITCHZERO> set-nsxedge $edge Edge Services Gateway update will modify existing Edge configuration. Proceed with Update of Edge Services Gateway mercury-esg1? [Y] Yes [N] No [?] Help (default is "N"): y id : edge-4 version : 37 status : deployed datacenterMoid : datacenter-2 datacenterName : Toronto tenant : hello name : mercury-esg1 fqdn : mercury-esg1.mercury.local enableAesni : true enableFips : false vseLogLevel : info vnics : vnics appliances : appliances cliSettings : cliSettings features : features autoConfiguration : autoConfiguration type : gatewayServices isUniversal : false hypervisorAssist : false tunnels : edgeSummary : edgeSummary