Over the years, I’ve been on quite a few network performance cases and have seen many reasons for performance trouble. One that is often overlooked is the impact of CPU contention and a VM’s inability to schedule CPU time effectively.
Today, I’ll be taking a quick look at the actual impact CPU scheduling can have on network throughput.
Testing Setup
To demonstrate, I’ll be using my dual-socket management host. As I did in my recent VMXNET3 ring buffer exhaustion post, I’ll be testing with VMs on the same host and port group to eliminate bottlenecks created by physical networking components. The VMs should be able to communicate as quickly as their compute resources will allow them.
Physical Host:
- 2x Intel Xeon E5 2670 Processors (16 cores at 2.6GHz, 3.3GHz Turbo)
- 96GB PC3-12800R Memory
- ESXi 6.0 U3 Build 5224934
VM Configuration:
- 1x vCPU
- 1024MB RAM
- VMXNET3 Adapter (1.1.29 driver with default ring sizes)
- Debian Linux 7.4 x86 PAE
- iperf 2.0.5
The VMs I used for this test are quite small with only a single vCPU and 1GB of RAM. This was done intentionally so that CPU contention could be more easily simulated. Much higher throughput would be possible with multiple vCPUs and additional RX queues.
The CPUs in my physical host are Xeon E5 2670 processors clocked at 2.6GHz per core. Because this processor supports Intel Turbo Boost, the maximum frequency of each core will vary depending on several factors and can be as high as 3.3GHz at times. To take this into consideration, I will test with a CPU limit of 2600MHz, as well as with no limit at all to show the benefit this provides.
To measure throughput, I’ll be using a pair of Debian Linux VMs running iperf 2.0.5. One will be the sending side and the other the receiving side. I’ll be running four simultaneous threads to maximize throughput and load.
I should note that my testing is far from precise and is not being done with the usual controls and safeguards to ensure accurate results. This said, my aim isn’t to be accurate, but rather to illustrate some higher-level patterns and trends.
Simulating CPU Contention
The E5 2670 processors in my host have plenty of power for home lab purposes, and I’m nowhere near CPU contention during day-to-day use. An easy way to simulate contention or CPU scheduling difficulty would be to manually set a CPU ‘Limit’ in the VM’s resource settings. In my tests, this seemed to be quite effective.
The challenge I had was what appeared to be a brief period of CPU burst that occurs before the set limit is enforced. For the first 10 seconds of load, the limit doesn’t appear to work and then suddenly kicks in. To circumvent this, I ran an iperf test until I saw the throughput drop, cancelled it, and then started the test again immediately for the full duration. This ensured that the entire test was done while CPU limited.
With an enforced limit, the receiving VM (iperf-test2) simply couldn’t get sufficient scheduling time with the host’s CPU during load. CPU ready time was very high as a result.
Below is esxtop output illustrating the effect:
ID GID NAME NWLD %USED %RUN %SYS %WAIT %VMWAIT %RDY %IDLE %OVRLP %CSTP %MLMTD %SWPWT 5572782 5572782 iperf-test2 6 66.50 32.82 28.20 571.70 0.17 0.12 67.73 0.01 0.00 0.00 0.00 5572767 5572767 iperf-test1 6 37.77 29.20 3.56 505.83 0.13 69.60 3.19 0.02 0.00 69.52 0.00 19840 19840 NSX_Controller_ 9 11.60 12.63 0.36 894.20 0.00 0.17 391.13 0.04 0.00 0.00 0.00 19825 19825 NSX_Controller_ 9 9.22 10.43 0.11 896.38 0.00 0.19 392.96 0.08 0.00 0.00 0.00 20529 20529 vc 10 9.13 11.97 0.14 995.69 0.53 0.14 189.26 0.03 0.00 0.00 0.00 <snip>
With a CPU limit of 800MHz, we can see a very high CPU %RDY time of about 69%. This tells us that the guest was ready to schedule work for the CPU to do, but 69% of the time it couldn’t get scheduling time.
Let’s have a look at the test results.
Interpreting The Results
To simulate varying degrees of contention, I re-ran the test described in the previous section after decreasing the CPU limit in 200MHz intervals. Below is the result:
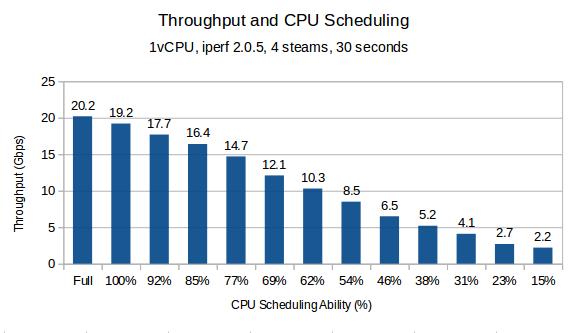
The actual results including the CPU limit set is as follows:
No Limit (Full Frequency): 20.2 Gbps
2600MHz (100%): 19.2 Gbps
2400MHz (92%): 17.7 Gbps
2200MHz (85%): 16.4 Gbps
2000MHz (77%): 14.7 Gbps
1800MHz (69%): 12.1 Gbps
1600MHz (62%): 10.3 Gbps
1400MHz (54%): 8.5 Gbps
1200MHz (46%): 6.5 Gbps
1000MHz (38%): 5.2 Gbps
800MHz (31%): 4.1 Gbps
600MHz (23%): 2.7 Gbps
400MHz (15%): 2.2 Gbps
The end result was surprisingly linear and can tell us several important facts about this guest.
- CPU was clearly a bottleneck for this guest to process frames. Throughput continues to scale as CPU scheduling time increased.
- This guest probably wouldn’t have difficulty with 10Gbps networking throughput levels until it’s CPU scheduling ability dropped below 70%.
- With Gigabit networking, this guest had plenty of cycles to process frames.
Realistically, this guest would be suffering from many other performance issues with CPU %RDY times that high, but it’s interesting to see it’s impact on the network stack and with frame processing.
Conclusion
My tests were far from accurate, but they help to illustrate the importance of having ample CPU scheduling time for high network throughput. If your benchmarks or throughput levels aren’t where they should be, you should definitely have a look at your CPU %RDY times.
Stay tuned for other tests. In a future post, I hope to examine the role offloading features like LRO and TSO play in throughput testing. Please feel free to leave any questions or comments below!

One thought on “VM Network Performance and CPU Scheduling”