When I built my new compute nodes, I chose PC3L-12800R DIMMs that could run in both standard 1.5V and 1.35V low-voltage modes. What I didn’t realize, however, is that Intel’s specification for 1.35V registered memory on Socket R based systems limits low-voltage operation to 1333MHz. The Supermicro X9SRL-F boards I’m using enforce this, despite the modules being capable of the full 1600MHz at 1.35V.
This meant I could run the modules at 1333MHz and enjoy the power/heat reduction that goes with 1.35V operation, or I could force the modules to run at 1600MHz at the ‘standard’ 1.5 volts. As I considered different configuration options, a lot of questions came to mind. Today I’ll be taking an in-depth look at DDR3 memory bandwidth, latency, power consumption and heat. I hope to answer the following questions in this post:
- What is the bandwidth difference between 1333MHz with tighter 9-9-9 timings versus 1600MHz at looser 11-11-11 timings?
- What is the latency difference between 1333MHz with tighter 9-9-9 timings versus 1600MHz at looser 11-11-11 timings?
- Just how much power savings can be realized at 1.35V versus 1.5V?
- How much cooler will my DIMMs run at 1.35V versus 1.5V?
- What about overclocking my DIMMs to 1867MHz at 12-12-12 timings?
- How does memory bandwidth and latency fair with fewer than 4 DIMMs populated on the SandyBridge-EP platform?
A Note On Overclocking
Although there are IvyBridge-EP CPUs that support higher 1866MHz DIMM operation, my SandyBridge-EP based E5-2670s and PC3L-12800 DIMMs do not officially support this. The Supermicro X9SRL-F allows the forcing of 1866MHz at 12-12-12 timings even though the DIMMs don’t have this speed in their SPD tables. Despite being server-grade hardware, this is an ‘overclock’ plain and simple.
I would never consider doing this in a production environment, but in a lab for educational purposes – it was worth a shot. Thankfully, to my surprise, the system appears completely stable at 1866MHz and 1.5V. Because the DIMMs can technically run at 1600MHz with a lower 1.35V, it would seem logical that at 1.5V they’d have additional headroom available. This certainly appears to be true in my case – even with a mixture of three different brands of PC3L-12800R.
With my overclocking success, I decided to include results for 1866MHz operation at 1.5V to see if it’s worth pushing the DIMMs beyond their rated specification.
Bandwidth and Latency
Back in my days as an avid overclocker, increasing memory frequency would generally provide better overall performance than tightening the CAS, RAS and other timings of the modules. Obviously doing both was ideal but if you had to choose between higher frequency and tighter timings, you’d usually come out ahead by sacrificing tighter timings for higher frequencies.
I fully expected the 1600MHz memory running at 11-11-11 timings to be quicker overall than 1333MHz at 9-9-9, but the question was just how much quicker. To test, I booted one of my X9SRL-F systems from a USB stick running Lubuntu 18.04 and used Intel’s handy ‘Memory Latency Checker’ (MLC) tool. MLC allows you to get several performance metrics including peak bandwidth, latency as well as various cross-socket NUMA measurements that can be handy for multi-socket processor systems. I’ll only be looking at a few metrics:
- Peak Read Bandwidth
- 1:1 Reads/Writes Bandwidth
- Idle Latency
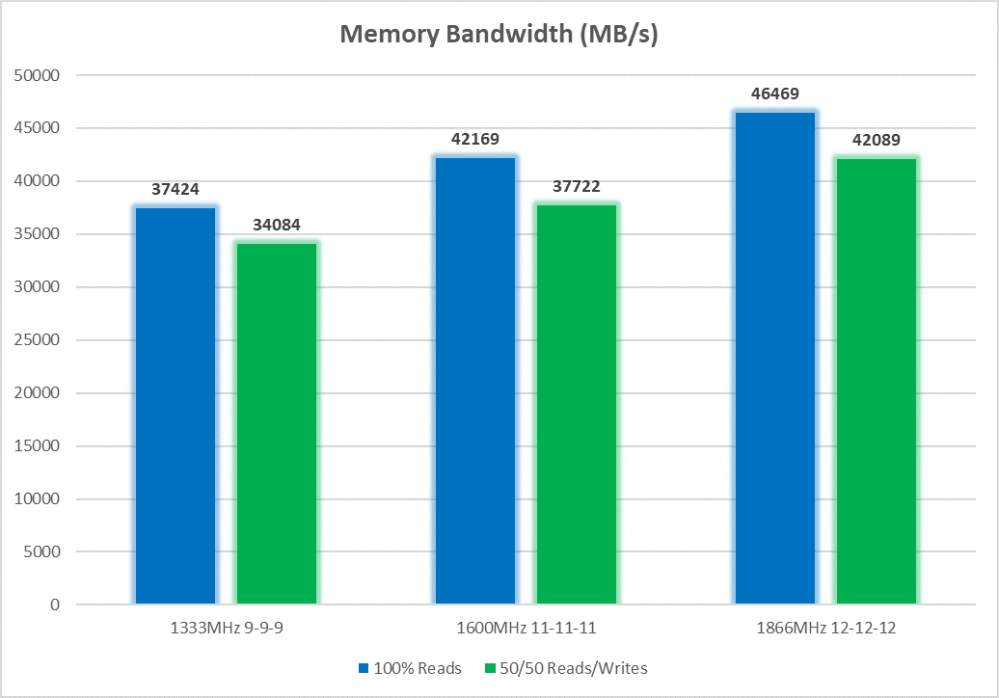
As I expected, despite the looser timings, memory bandwidth increases substantially as the frequency increases. About a 12% boost is obtained going to 1600MHz at 11-11-11 timings. An additional 10% was obtained by overclocking the modules to 1866MHz. Mixed reads and writes get a pretty proportional boost in all three tests.
Continue reading “Low-Voltage DDR3 – Performance, Heat and Power”