Welcome to the second installment of a new series of NSX troubleshooting scenarios. This is the second half of scenario two, where I’ll perform some troubleshooting and resolve the problem.
Please see the first half for more detail on the problem symptoms and some scoping.
Getting Started
As mentioned in the first half, the problem is limited to a host called esx-a1. As soon as a guest moves to that host, it has no network connectivity. If we move a guest off of the host, its connectivity is restored.

We have one VM called win-a1 on host esx-a1 for testing purposes at the moment. As expected, the VM can’t be reached.
To begin, let’s have a look at the host from the CLI to figure out what’s going on. We know that the UI is reporting that it’s not prepared and that it doesn’t have any VTEPs created. In reality, we know a VTEP exists but let’s confirm.
To begin, we’ll check to see if any of the VIBs are installed on this host. With NSX 6.3.x, we expect to see two VIBs listed – esx-vsip and esx-vxlan.
Sure enough, they are not listed as installed. The UI is correct:
[root@esx-a1:~] esxcli software vib list |grep -E 'vsip|vxlan' [root@esx-a1:~]
For comparison purposes, here is the expected output on host esx-a2:
[root@esx-a2:~] esxcli software vib list |grep -E 'vsip|vxlan' esx-vsip 6.5.0-0.0.5534171 VMware VMwareCertified 2017-11-10 esx-vxlan 6.5.0-0.0.5534171 VMware VMwareCertified 2017-11-10
Either the VIB install failed, or they were not installed at all. We’ll come back to this but without these VIBs on the host, VXLAN networking will not function, nor will the DFW. We can see that the DFW fast path filters don’t exist on the host – vsip and the dvfilter-switch-security:
[root@esx-a1:~] summarize-dvfilter |head Fastpaths: agent: dvfilter-faulter, refCount: 1, rev: 0x1010000, apiRev: 0x1010000, module: dvfilter agent: ESXi-Firewall, refCount: 5, rev: 0x1010000, apiRev: 0x1010000, module: esxfw agent: dvfilter-generic-vmware, refCount: 2, rev: 0x1010000, apiRev: 0x1010000, module: dvfilter-generic-fastpath agent: dvfg-igmp, refCount: 1, rev: 0x1010000, apiRev: 0x1010000, module: dvfg-igmp Slowpaths: Filters: world 0 <no world>
The net-vdl2 and net-vdr tools we’d use for troubleshooting VXLAN and distributed routing are also not on the host:
[root@esx-a1:~] net-vdl2 -l -sh: net-vdl2: not found [root@esx-a1:~] net-vdr -I -l -sh: net-vdr: not found
What is odd, however, is that we have a VTEP vmkernel port associated with the VXLAN networking stack on host esx-a1:
[root@esx-a1:~] esxcfg-vmknic -l |grep -i vxlan vmk3 175 IPv4 172.16.76.22 255.255.255.0 172.16.76.255 00:50:56:6e:0c:77 1500 65535 true STATIC vxlan
Normally, whenever a host is added to an NSX prepared cluster, the NSX VIBs are installed, then API calls are used to create the VTEPs. We will need to look into this further because if the VIBs weren’t installed, the VTEP should not have been created either. Another possibility is that it was never deleted when the host was removed from the cluster, or it may have been added manually.
From the UI, it appears that NSX doesn’t know about this VTEP. We can see that a VXLAN error reports that the VTEP was not created successfully.

We can clearly see in the Logical Network Preparation section that host esx-a1 should have one VTEP, but from the perspective of NSX, doesn’t have any:

This may appear to be an odd inconsistency between what’s in the UI and what’s visible on the host, but it tells us something very important. If it doesn’t appear in the Logical Network Preparation page, we know that it doesn’t exist in the NSX database. If it doesn’t exist in the database, NSX has no knowledge of it and all bets are off. This is what I like to refer to as an ‘orphaned’ VTEP.
So we know the following:
- Host esx-a1 was added to the NSX prepared cluster compute-a, which should have triggered both VIB installation and VTEP creation.
- NSX host VIBs are definitely not installed on host esx-a1.
- The VXLAN vmkernel port that exists on host esx-a1 is effectively ‘orphaned’ as NSX knows nothing about it.
- VXLAN networking cannot function without the esx-vxlan VIB module installed, nor will the DFW function without esx-vsip.
- We know why VMs won’t work on this host and now have a better understanding of it’s current state.
What Should Have Happened?
The next logical question is: “If host esx-a1 was added to an NSX prepared cluster, why doesn’t it have the VIBs installed?”
Before we starting digging into why this happened, let’s have a look at the normal sequence of events that occurs in 6.3.x when a host is removed and added to a cluster. Below is the normal events you’d observe in the vSphere Web Client when removing a host:

Some of the key tasks to note are the removal of the VIBs, the deletion of the VTEP vmkernel port and the removal of the EAM (ESX Agent Manager) agent that keeps track of the installation/deployment status.
In a normal and healthy environment, when a host is added to an NSX prepared cluster, you’d see tasks and events similar to:
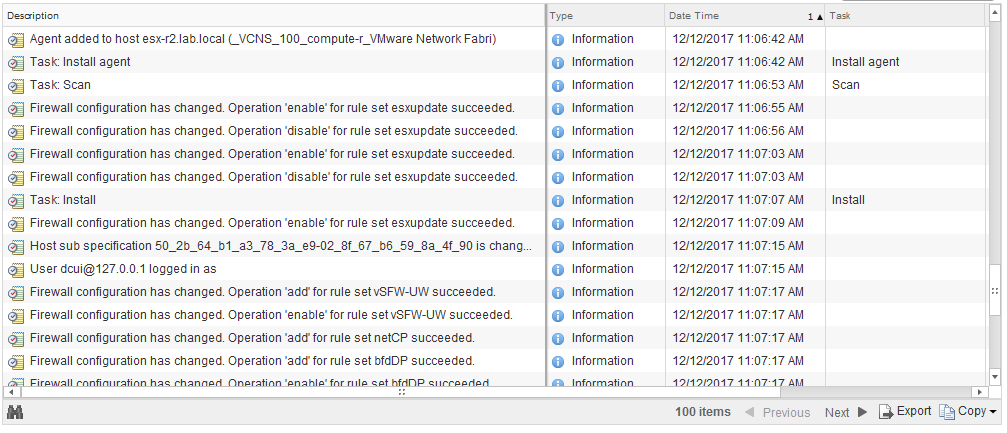
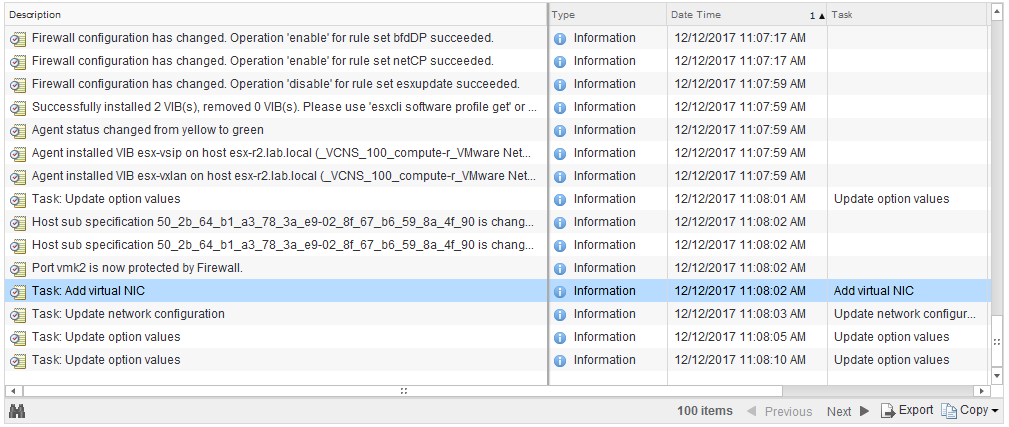
I won’t get into too much detail on the process – maybe in a future post – but I’ll call out some key points. First, we see that EAM (ESX Agent Manager) creates an EAM ‘agent’ entry for the host. It then does a scan of the host to see if it has the correct version of the VIBs already installed or not. If not, the VIBs are installed. After that is completed, the VTEP vmkernel port will be created based on the VXLAN configuration defined in NSX.
There is obviously a lot more happening in the background while this occurs but on the surface, this is what we should see when a host is removed and added.
Tasks and Events – A Telling History
So where did host esx-a1 go wrong? Let’s have a look at the Tasks and Events to see.

I can see that the host was put into maintenance mode and removed from the cluster a few weeks back. All the uninstall tasks and VTEP removal operations completed successfully. The host was also successfully removed from the EAM agency. For all intents and purposes, NSX forgot everything about this host at that time.
Whatever happened, it wasn’t due to incorrect removal. One other point I should mention is that in 6.3.x, we benefit from not having to reboot after VIB upgrade, installation, or removal. The host simply needs to be in maintenance mode. If this were a 6.2.x NSX deployment, we would need to reboot the host after VIB removal to complete the ‘unprep’ process.
Let’s see if we can figure out the date/time the host was added back to the cluster.
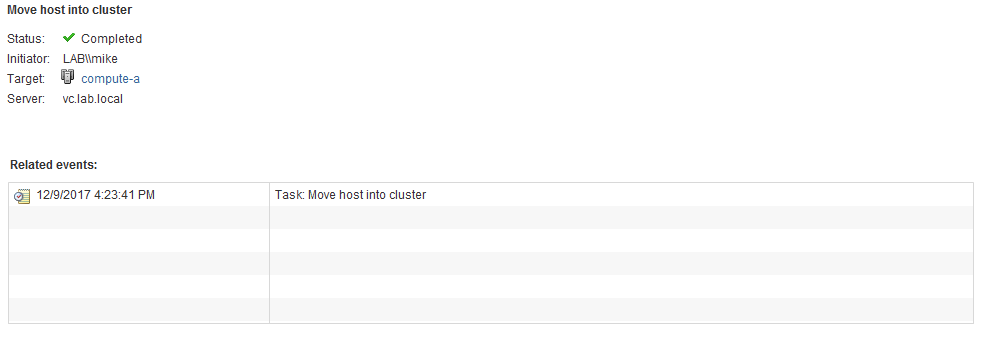
Host esx-a1 was added back into the compute-a cluster at 4:23 on 12/9. Let’s have a look to see if the expected tasks occurred at that time:

As you can see above, after the host was added to the cluster, it was taken out of maintenance mode about a minute later. Absolutely none of the expected NSX related preparation tasks were executed on host esx-a1!
We can confirm this as well in the /var/log/esxupdate.log file. Normally we’d see evidence of VIB installation, but nothing at all was there around this time stamp. Below is what we should have seen (taken from another host):
2017-12-12T16:06:54Z esxupdate: 7483051: HostImage: INFO: Attempting to download VIB esx-vsip^@ 2017-12-12T16:06:54Z esxupdate: 7483051: downloader: DEBUG: Downloading https://vc-rem.lab.local:443/eam/vib?id=d891957e-6332-40f7-b731-9e9fc2d6fed4 to /tmp/vibdownload/VMware_bootbank_esx-vsip_6.5.0-0.0.5534171.vib...^@ 2017-12-12T16:06:55Z esxupdate: 7483051: HostImage: INFO: Attempting to download VIB esx-vxlan^@ 2017-12-12T16:06:55Z esxupdate: 7483051: downloader: DEBUG: Downloading https://vc-rem.lab.local:443/eam/vib?id=e800f2f8-9805-4c8f-9dcb-b86ebb233733 to /tmp/vibdownload/VMware_bootbank_esx-vxlan_6.5.0-0.0.5534171.vib...^@ <snip> 2017-12-12T16:06:56Z esxupdate: 7483051: LiveImageInstaller: DEBUG: Live installing esx-vsip-6.5.0-0.0.5534171^@ 2017-12-12T16:06:56Z esxupdate: 7483051: LiveImageInstaller: DEBUG: Trying to mount payload [esx-vsip]^@ 2017-12-12T16:06:56Z esxupdate: 7483051: LiveImageInstaller: DEBUG: Mounting esx_vsip.v00...^@ 2017-12-12T16:06:56Z esxupdate: 7483051: vmware.runcommand: INFO: runcommand called with: args = 'mv /tmp/img-stg/data/esx_vsip.v00 /tardisks/', outfile = 'None', returnoutput = 'True', timeout = '0.0'.^@ 2017-12-12T16:06:57Z esxupdate: 7483051: LiveImageInstaller: DEBUG: Live installing esx-vxlan-6.5.0-0.0.5534171^@ 2017-12-12T16:06:57Z esxupdate: 7483051: LiveImageInstaller: DEBUG: Trying to mount payload [esx-vxla]^@ 2017-12-12T16:06:57Z esxupdate: 7483051: LiveImageInstaller: DEBUG: Mounting esx_vxla.v00...^@ 2017-12-12T16:06:57Z esxupdate: 7483051: vmware.runcommand: INFO: runcommand called with: args = 'mv /tmp/img-stg/data/esx_vxla.v00 /tardisks/', outfile = 'None', returnoutput = 'True', timeout = '0.0'.^@ip>
In fact, after the problems started, we can see that a user called mike@lab.local manually tinkered with vmkernel ports after opening a console session to the win-a1 VM:
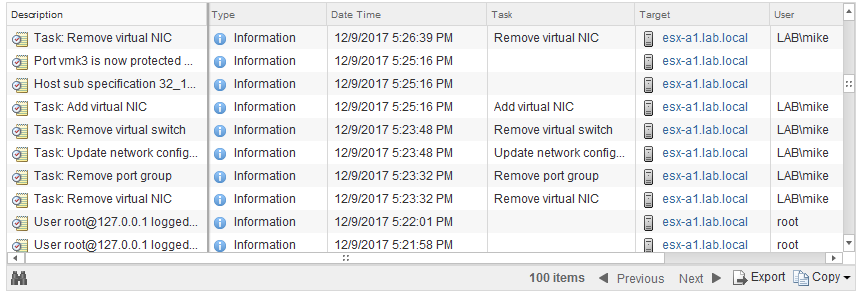
We know that this wasn’t NSX because NSX uses the account used to link NSX Manager to VC. In this case, it is administrator@vsphere.local. This user probably noticed that the vmkernel VTEP was missing and manually created it to fix the problem. Although the kernel port was created with the same IP and associated with the correct network stack in ESXi, it would simply not work. NSX has no knowledge of it. To make matters worse, because its IP was statically assigned and not assigned out from the correct IP pool, it’s likely that IP conflicts would occur in the future.
Narrowing It Down!
Taking a look again at the tasks and events, we know that none of the expected NSX related tasks were executed when host esx-a1 was added back to the cluster. More specifically, we know that the very first task never happened – creating an EAM agent entry for the host and then scanning it for VIBs.
EAM or ESX Agent Manager is a component often not well understood. Despite it being used almost exclusively by NSX, it’s actually a component of vCenter Server – not NSX Manager. EAM is responsible for keeping track of agent module installation and status on a per cluster basis. Each cluster consists of an EAM ‘Agency’ made up of one or more EAM ‘Agents’ – one per ESXi host. Tasks executed by EAM can be easily identified as they are executed by a user called com.vmware.vim.eam.
We know that EAM did not do anything as a result of adding host esx-a1 back into the cluster, so our focus needs to be squarely on EAM.
To begin, let’s have a look at the health of the EAM Agency associated with cluster compute-a. We can check EAM status by going to Administration and then vCenter Server Extensions in the Web Client.
As mentioned, there should be one EAM Agency per cluster – we see nothing at all. This is definitely not the view we expect to see here.

Not only this, but a brief ‘503’ error popped up when I arrived at this page:
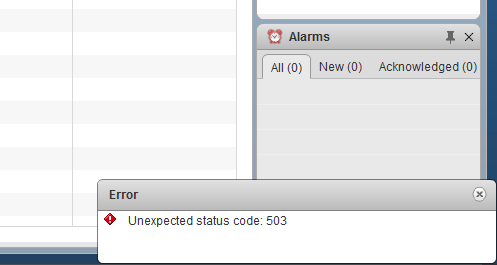
An HTTP 503 error code simply implies that the service is unavailable. I’m going to check the EAM MOB (Managed Object Browser) from a browser to see if we get a similar result:

We do. It appears that EAM is not running or has crashed. I’m going to check on the service status now from the Web Client:
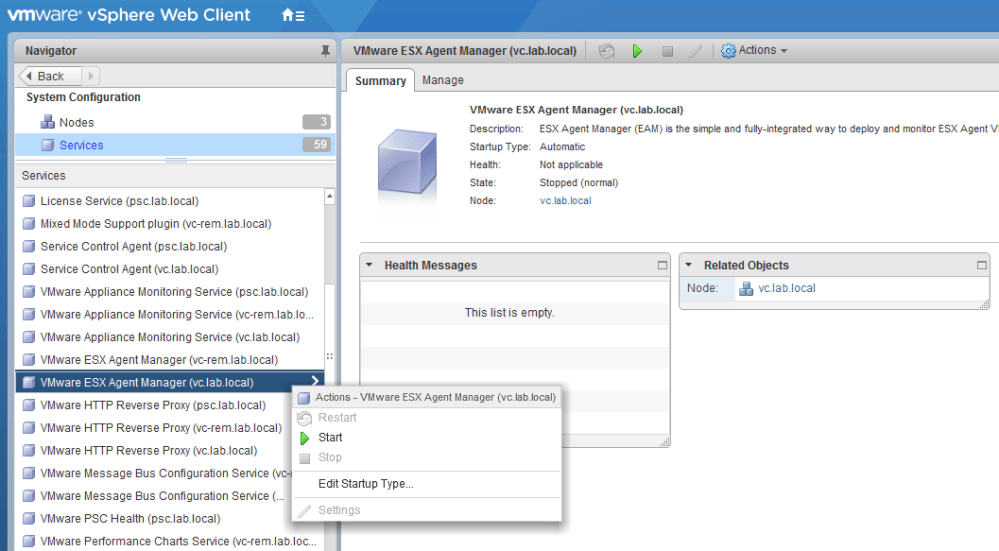
The EAM service is not running. This explains why no action was taken when host esx-a1 was added to the cluster! Let’s start the service and see what happens.

Immediately we see a bunch of scan tasks kick off, which is a normal operation after EAM starts. There are also ‘Install agent’ tasks for each host, but if the VIBs are already there will simply complete without installing anything on the hosts. Only host esx-a1 seems to be taking more time for the ‘Install agent’ task because the VIBs are actually being installed.
After the VIB install completes, we see that many failed vmkernel creation attempts follow:

The reason for this is because NSX is trying to create the VTEP using 172.16.76.22, which is already being used by the manually created VTEP vmkernel port on the host. We can see the failure details in the /var/log/vmkernel.log file:
2017-12-12T17:52:26.423Z cpu2:67720 opID=2bf63fd9)NetPort: 1660: enabled port 0x2000030 with mac 00:50:56:64:71:90 2017-12-12T17:52:26.423Z cpu2:67720 opID=2bf63fd9)vxlan: VDL2GetlEndpointAndSetUplink:381: Now, no active uplinks in tunnel group:33554446. 2017-12-12T17:52:26.424Z cpu2:67720 opID=2bf63fd9)WARNING: Tcpip_Vmk: 659: Duplicate IP address: port already uses 0x164c10ac
Cleaning Up
At this stage, EAM is back up and running. We know that VIB installs are possible again and NSX does try to deploy the VTEP to the host. Now, the easiest and cleanest way to get things back into a good state is to simply remove the host from the cluster, remove the orphaned VTEP and then add it back into the cluster.
Once out of the cluster, we know that any vmkernel ports associated with the VXLAN network stack are effectively useless and safe to remove. These should only ever exist while in an NSX prepared cluster.
Note: Again, don’t forget – if you are running NSX 6.2.x or an older version, you have to reboot the host after removing it from the cluster to complete the uninstall.
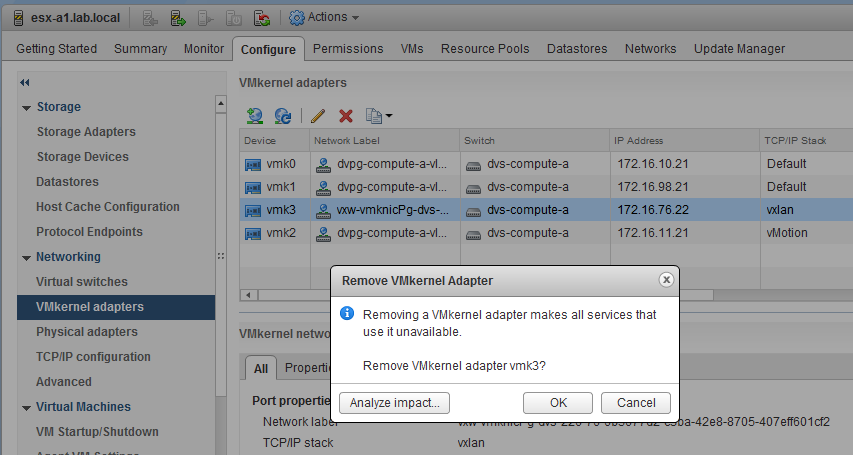
Once the kernel port is removed and we see the host no longer showing up in the NSX Host Preparation tab, we can add it back to the cluster and check to ensure the VTEP is created successfully this time.

This time around, all of the expected tasks were executed, and we can see the host is in a healthy state.
Conclusion
I purposely didn’t get too much into why the EAM service had been stopped as troubleshooting EAM could be a series of articles in and of itself. I was more interested in illustrating a few important points:
- EAM plays an important role when it comes to host preparation. It orchestrates the preparation and removal of hosts in an NSX cluster. Without it, hosts being added won’t function.
- Objects created in an automated fashion by NSX – like VTEPs – are often not the equivalent of manually created objects in their place. As you saw, NSX keeps track of VTEPs in the database and tracks IP assignment via pool reservations. Creating these manually is never a good idea.
- Monitoring the tasks and events and understanding what’s expected when a host is added or removed really helps when it comes to troubleshooting host preparation issues.
Thanks for reading! I hope you enjoyed this scenario. If you have other suggestions for troubleshooting scenarios you’d like to see, please leave a comment or reach out to me on Twitter (@vswitchzero).

Thank you for putting together another problem / solution scenario.
Also, thanks for putting in the CLI commands and example output.
Keep them coming!