I got some overwhelmingly positive feedback after posting the first troubleshooting scenario and solution recently. Thanks to everyone who reached out to me via Twitter with feedback and suggestions! Please keep those suggestions and comments coming.
Today, I’m going to post a similar but more brief scenario. This is something that we see regularly in GSS – issues surrounding host preparation!
NSX Troubleshooting Scenario 2
Let’s begin with the usual vague customer problem description:
“We took a host out of the compute-a cluster to do some hardware maintenance. Now it’s been added back and when VMs move to this host, they have no connectivity! We’re using NSX 6.3.2”
This is a fictional scenario of course, but let’s assume that we’ve started taking a look at the environment and collecting some additional data.
As the customer mentioned, they are running NSX 6.3.2 and have a cluster called compute-a:
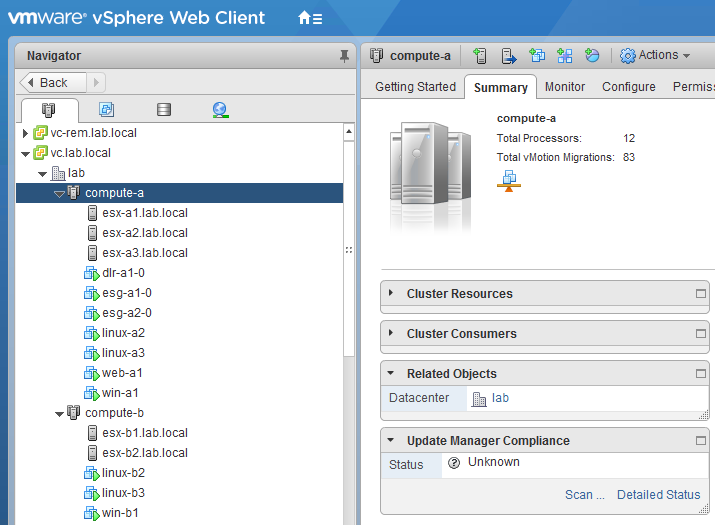
The host that was taken out of the cluster for maintenance was esx-a1.lab.local. Similar to the previous scenario, the L3 design is pretty much the same:

The web-a1 VM was migrated to each host, and the customer has confirmed that whenever it goes to host esx-a1, it can’t ping anything. The vMotion operation always completes successfully.
From a console of the web-a1 VM, the following destinations were tested:
- Default gateway (DLR at 172.17.1.1)
- DNS Server (172.16.10.10)
- Internet Location (8.8.8.8)
- Upstream router (172.17.0.10)
- VM in the same subnet/VXLAN and in compute-a cluster (172.17.1.12)
- VM in the same subnet/VXLAN and in compute-b cluster (172.17.1.35)
None of the above worked.
As soon as the VM is migrated back to esx-a2.lab.local or esx-a3.lab.local, it can communicate once again.
The web-a1 virtual machine is currently in VXLAN 5001 called the ‘Blue Network’:
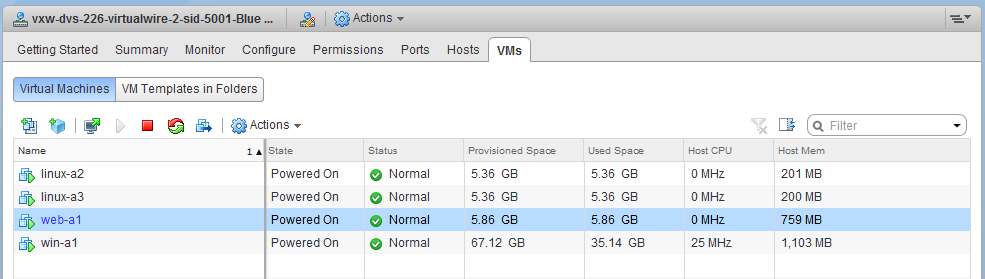
Taking a look in the NSX vSphere Client UI, we can see that the NSX manager and controllers appear to be in good shape:

The Host Preparation page shows that host esx-a1 is not prepared for some reason!
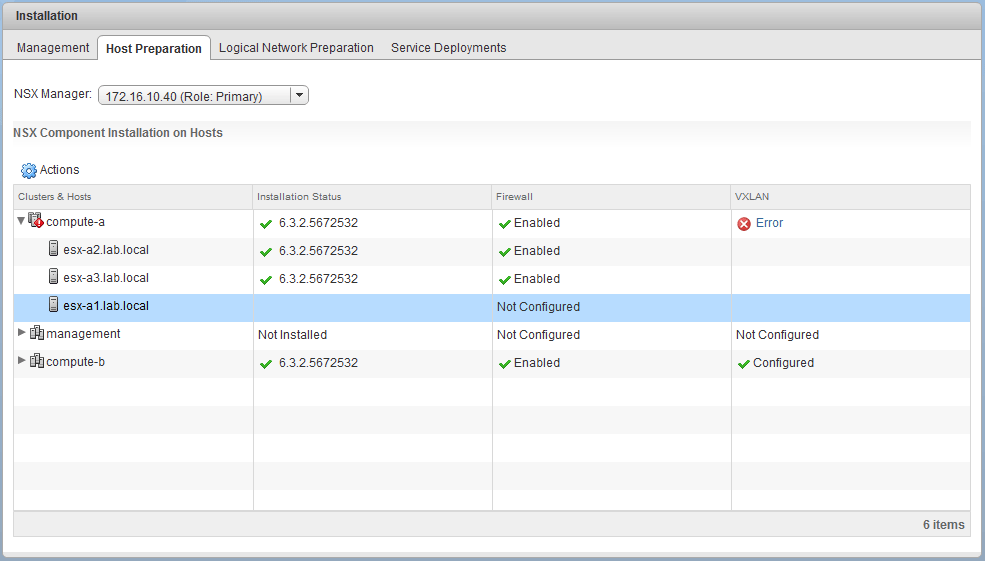
There is also a VXLAN error that reads:
“VTEP has not been created successfully on the Host.”
Oddly though, if we look at the vmkernel adapter view of the vSphere Web Client, we can see a VXLAN VTEP that exists!
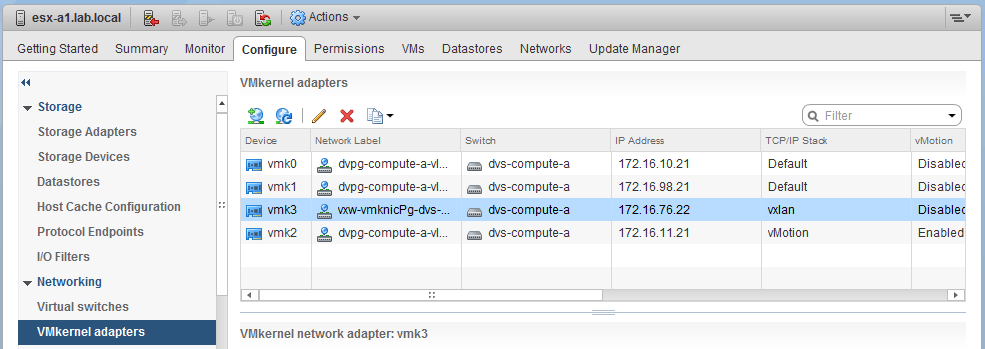
So is this host prepared or not? Either the UI is wrong or there is a problem. After asking the customer some more questions, we’ve been able to determine the steps they did with esx-a1 to get to this state. Unfortunately, the customer we’re talking to is not the same person who made the changes. That individual is on vacation now and can’t be reached – typical.
- Host esx-a1 was put into maintenance mode and evacuated of all VMs.
- Host esx-a1 was removed from the cluster.
- The host was then powered off.
- It took several weeks to get the replacement memory for the host, but eventually it was replaced.
- Host esx-a1 was powered back on and looked good from a hardware/vSphere perspective.
- Host esx-a1 was added back to the compute-a cluster. No errors were reported when this was done.
- The host was taken out of maintenance mode.
- After a day or two, DRS migrated some VMs to esx-a1 and that was when we noticed applications becoming inaccessible.
- To work around the issue, we migrated VMs that were on esx-a1 to other hosts in the cluster and then put DRS into manual mode to prevent anything else from moving to esx-a1.
The customer believes there may have been other things done during troubleshooting but is unsure.
What’s Next?
In a day or two I’ll post the solution and troubleshooting steps necessary to find the underlying cause of this problem. Have a look through the information provided above and let me know what you would check or what you think the problem may be! I want to hear your suggestions!
**EDIT 12/12/2017: The solution to troubleshooting scenario two is now live!
Not only do we want to figure out how things got into this state in the first place, but also how to fix this problem and get things back into a good state.
What other information would you need to see? What tests would you run? What do you know is NOT the problem based on the information and observations here?
Please feel free to leave a comment below or via Twitter (@vswitchzero).
