Welcome to the third installment of my new NSX troubleshooting series. What I hope to do in these posts is share some of the common issues I run across from day to day. Each scenario will be a two-part post. The first will be an outline of the symptoms and problem statement along with bits of information from the environment. The second will be the solution, including the troubleshooting and investigation I did to get there.
NSX Troubleshooting Scenario 3
I’ll start off again with a brief customer problem description:
“We’ve recently deployed Cross-vCenter NSX for a remote datacenter location. All of the VMs at that location don’t have connectivity. They can’t ping their gateway, nor can they ping VMs on other hosts. Only VMs on the same host can ping each other.”
This is a pretty vague description of the problem, so let’s have a closer look at this environment. To begin, let’s look at the high-level physical interconnection between datacenters in the following diagram:
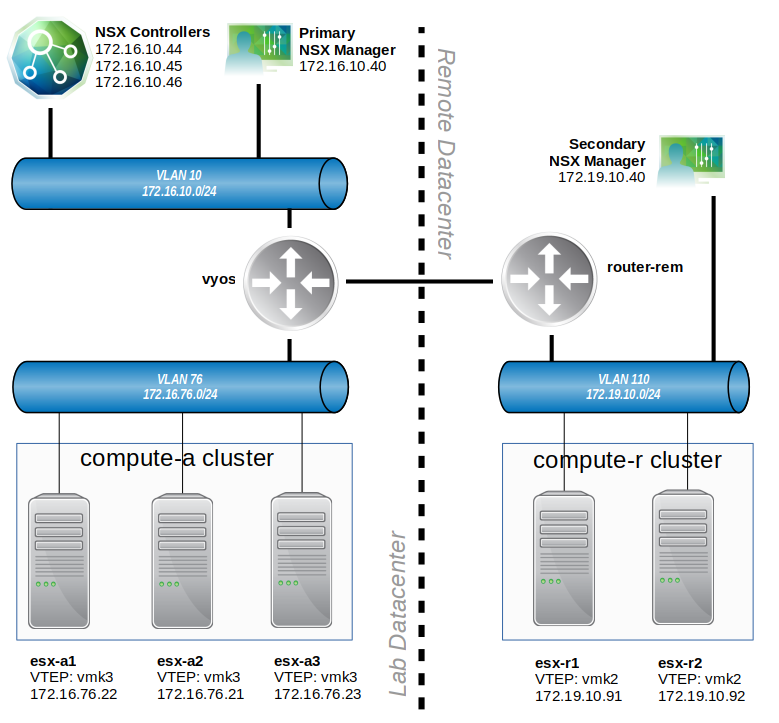
There isn’t a lot of detail above, but it helps to give us some talking points. The main location is depicted on the left. A three host cluster called compute-a exists there. All of the VLAN backed networks route through a router called vyos. The Universal Control Cluster exists at this location, as does the primary NSX manager.
The ‘remote datacenter’ depicted to the right of the dashed line is the new environment that was just added. A branch router at this location called router-rem has a high-speed point-to-point Ethernet WAN connection to the ‘lab datacenter’. A two host cluster exists here for compute resources, as does the secondary NSX manager.
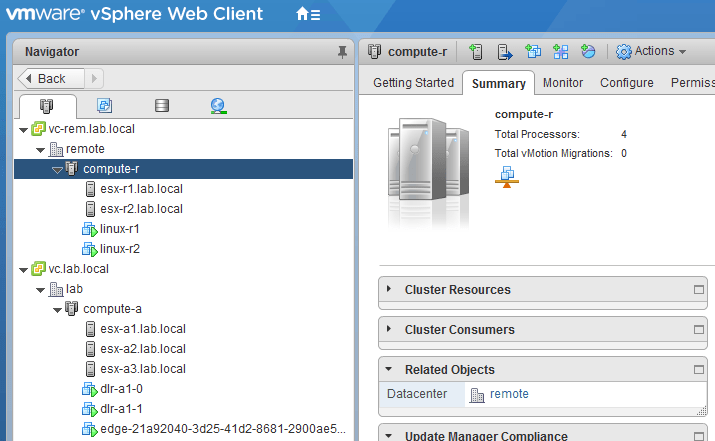
As expected, each datacenter has it’s own vCenter and NSX manager as per the cross-VC requirements:
Looking at the logical networking, including the universal logical switches, we can see a setup similar to the following:
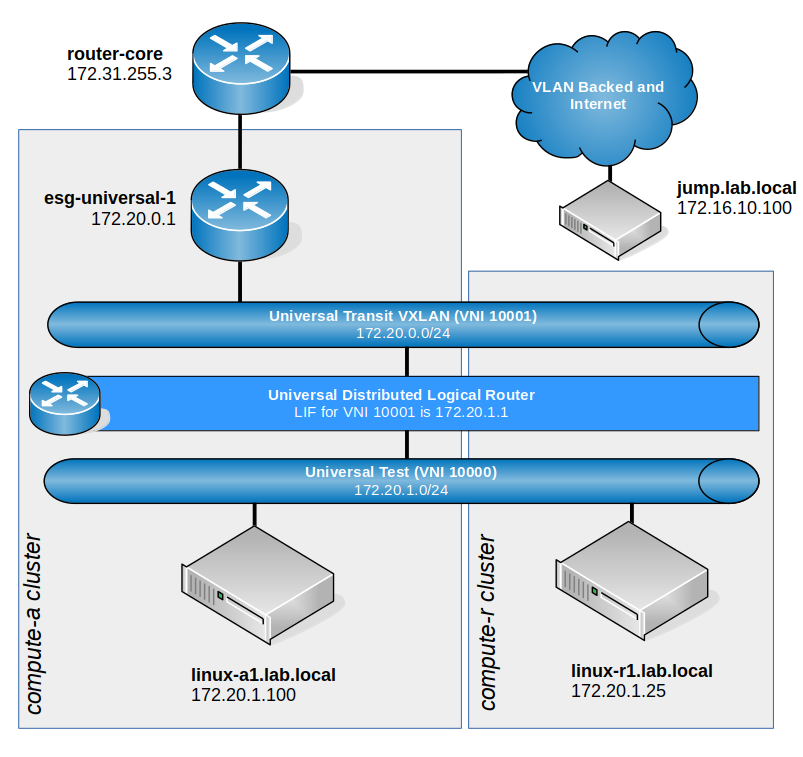 Again, this is pretty high level, but above you’ll notice that we are not using local egress. The ESG and DLR appliances exist in the compute-a cluster at the primary datacenter. Several universal logical switches span both datacenters, but the one the customer has been testing with is called ‘Universal Test’ with a VNI of 10000. A universal DLR provides routing between all universal logical switches and peers with esg-universal-1 via BGP.
Again, this is pretty high level, but above you’ll notice that we are not using local egress. The ESG and DLR appliances exist in the compute-a cluster at the primary datacenter. Several universal logical switches span both datacenters, but the one the customer has been testing with is called ‘Universal Test’ with a VNI of 10000. A universal DLR provides routing between all universal logical switches and peers with esg-universal-1 via BGP.
According to the customer, all the virtual machines in VNI 10000 are working just fine in the primary datacenter. They can ping each other, their gateways and all external addresses. Only VMs in VNI 10000 in the secondary location are unable to communicate with anything.
For simplicity in scoping and troubleshooting, we’ve identified two VMs to use for testing. One that works called linux-a1 at the primary location, and one called linux-r1 at the remote location.
Looking in the NSX Web Client UI, we can see that the NSX primary and secondary are in-sync and are not reporting any problems that we can see:
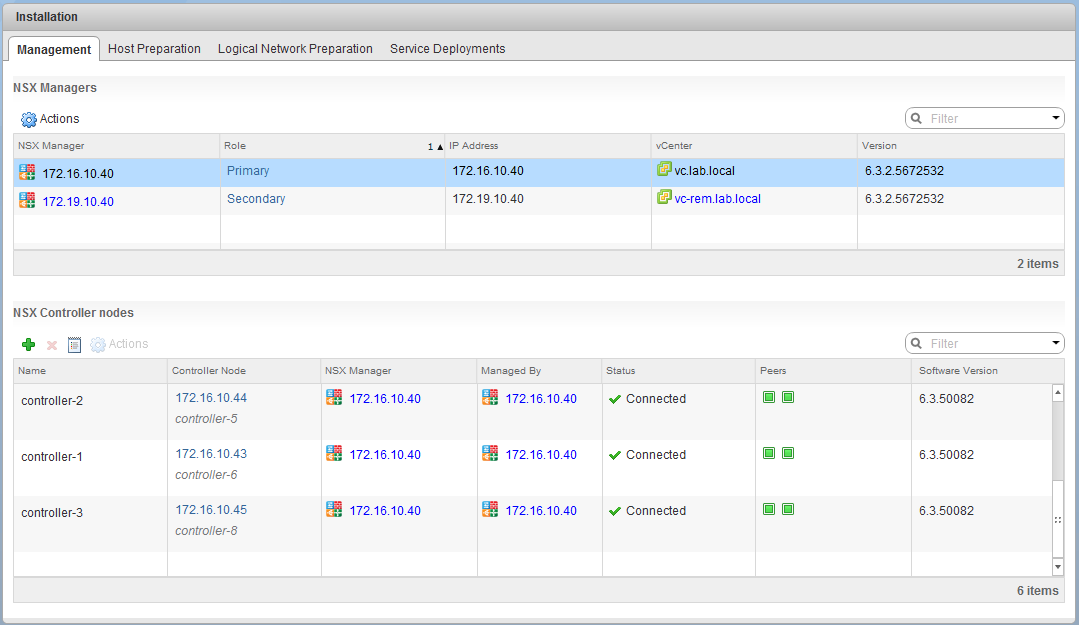
All three of the controller nodes at the primary location are connected and green. Remember – in a cross vCenter environment, only a single universal control cluster can exist. It’s normal not to have any controllers at the secondary location.
The ESXi hosts at the primary location look good. All VIBs are installed and Firewall and VXLAN looks green:
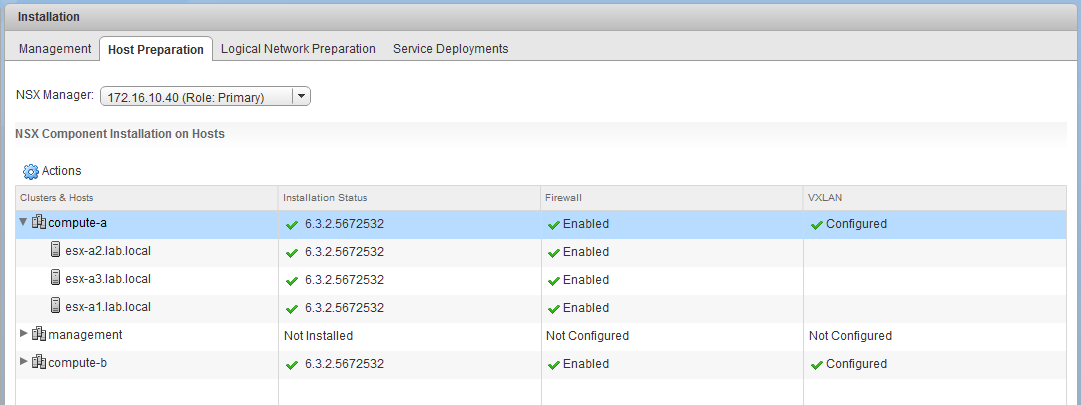
The same is true for the secondary location, but the hosts have red exclamation marks on them. This doesn’t seem to be related to installation status, firewall or VXLAN though:
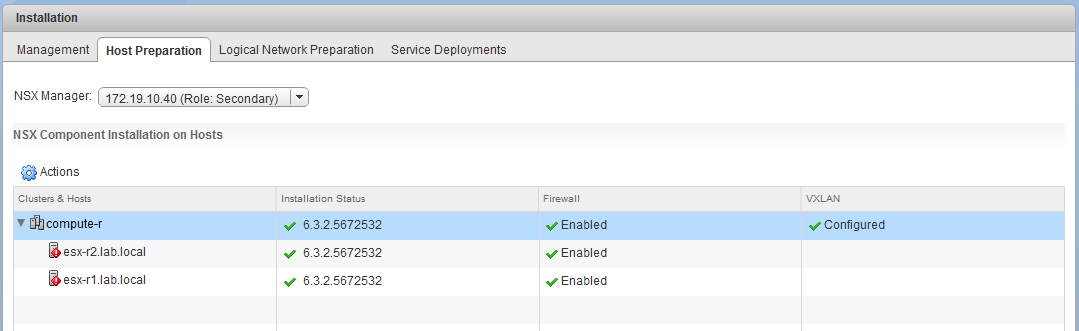
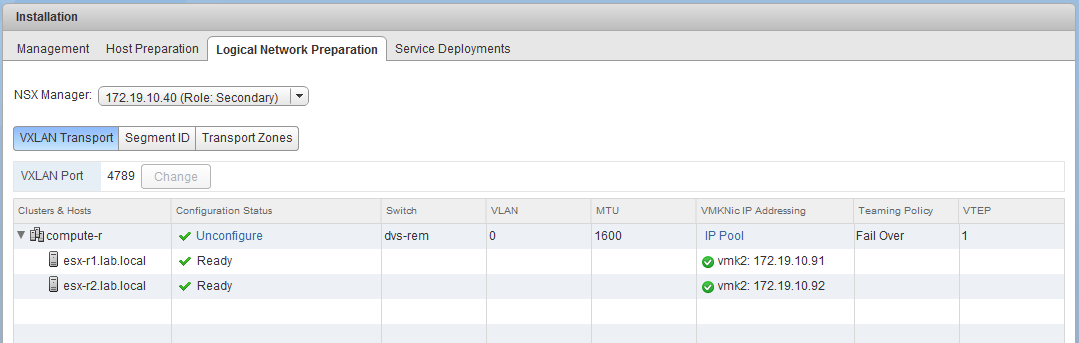
The VXLAN prep also looks good. Each host has a VTEP with the expected IP address assigned via the pool:
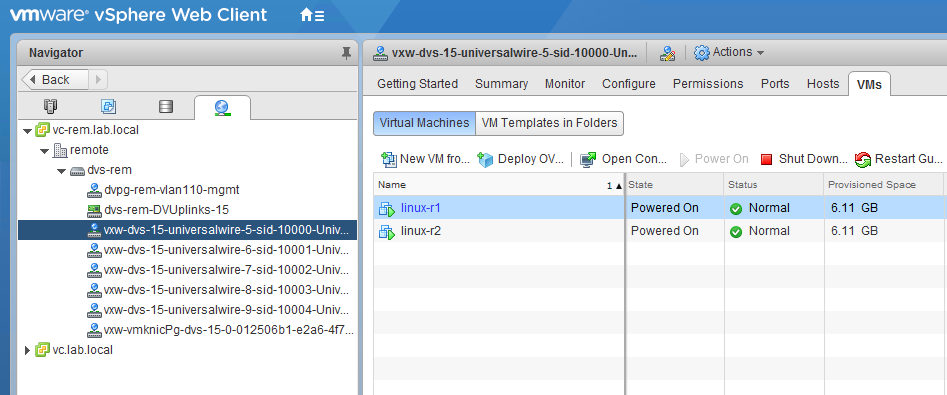
The compute-r cluster has it’s own distributed switch. It can’t share any of the others since this is a different vCenter instance. We can see that the VTEPs exist and that all of the logical switch dvPortgroups are indeed there:
Doing a few quick VTEP ping tests proves that hosts in compute-r can communicate with each other, and also with hosts in compute-a. This doesn’t appear to be an MTU or L3 datapath issue between the primary and secondary datacenters.
[root@esx-r1:~] ping ++netstack=vxlan -s 1572 -d 172.16.76.22 PING 172.16.76.22 (172.16.76.22): 1572 data bytes 1580 bytes from 172.16.76.22: icmp_seq=0 ttl=62 time=0.954 ms 1580 bytes from 172.16.76.22: icmp_seq=1 ttl=62 time=1.461 ms 1580 bytes from 172.16.76.22: icmp_seq=2 ttl=62 time=1.535 ms --- 172.16.76.22 ping statistics --- 3 packets transmitted, 3 packets received, 0% packet loss round-trip min/avg/max = 0.954/1.317/1.535 ms
Doing a traceroute also shows us that the path is only three hops away:
[root@esx-r1:~] traceroute ++netstack=vxlan 172.16.76.22 traceroute to 172.16.76.22 (172.16.76.22), 30 hops max, 40 byte packets 1 172.19.10.1 (172.19.10.1) 0.329 ms 0.166 ms 0.252 ms 2 172.31.255.1 (172.31.255.1) 0.229 ms 0.195 ms 0.181 ms 3 172.16.76.22 (172.16.76.22) 0.518 ms 0.539 ms 0.433 ms
This seems to coincide with the diagram provided.
The last thing we’ll check is the routing table on the DLR control VM. Let’s ensure the universal DLR has the routes we expect:
dlr-universal.lab.local-0> sh ip route Codes: O - OSPF derived, i - IS-IS derived, B - BGP derived, C - connected, S - static, L1 - IS-IS level-1, L2 - IS-IS level-2, IA - OSPF inter area, E1 - OSPF external type 1, E2 - OSPF external type 2, N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2 Total number of routes: 19 B 10.40.0.0/25 [200/0] via 172.20.0.1 B 172.16.10.0/24 [200/0] via 172.20.0.1 B 172.16.11.0/24 [200/0] via 172.20.0.1 B 172.16.12.0/24 [200/0] via 172.20.0.1 B 172.16.13.0/24 [200/0] via 172.20.0.1 B 172.16.14.0/24 [200/0] via 172.20.0.1 B 172.16.76.0/24 [200/0] via 172.20.0.1 B 172.16.77.0/24 [200/0] via 172.20.0.1 B 172.17.0.0/26 [200/0] via 172.20.0.1 B 172.17.1.0/24 [200/0] via 172.20.0.1 B 172.17.2.0/24 [200/0] via 172.20.0.1 B 172.17.3.0/24 [200/0] via 172.20.0.1 B 172.17.4.0/24 [200/0] via 172.20.0.1 B 172.17.5.0/24 [200/0] via 172.20.0.1 B 172.19.10.0/24 [200/0] via 172.20.0.1 C 172.20.0.0/24 [0/0] via 172.20.0.2 C 172.20.1.0/24 [0/0] via 172.20.1.1 B 172.30.30.30/32 [200/0] via 172.20.0.1 B 172.31.255.0/26 [200/0] via 172.20.0.1
We see all of the correct routes learned via BGP, including those connected routes for the Transit VXLAN and universal VNI 10000.
So now that we’ve looked around and have seen the environment, let’s summarize some of the initial scoping done:
- All VMs in VNI 10000 in compute-a work fine. They can ping each other on the same host, different hosts and also reach external addresses.
- VMs in VNI 10000 in compute-r can only ping each other when on the same host. They can’t ping each other on different hosts.
- VMs in VNI 10000 in compute-r can’t ping their default gateway. According to diagrams, this should be the universal DLR LIF.
- NSX universal synchronization appears to be good.
- VIB installation on all hosts looks good, including those in compute-a and compute-r.
- The control-cluster is green.
- VXLAN VTEPs can communicate between the two datacenters.
- A 1600 MTU seems to be okay between datacenters.
What’s Next?
If you are interested, have a look through the information provided above and let me know what you would check or what you think the problem may be! I want to hear your suggestions!
What other information would you need to see? What tests would you run? What do you know is NOT the problem based on the information and observations here?
**Edit 1/15/2018: The solution for scenario 3 is now live. You can find it here.
I will update this post with a link to the solution as soon as it’s completed. Please feel free to leave a comment below or via Twitter (@vswitchzero).

Hi Mike,
Thank you for the detailed explanation.in my opinion , i would perform many tests, but really each test depends on the previous one.
1. I would check first, if hosts have connectivity to Controllers.VMs can’t ping other VM in different host, mainly because hosts can’t reach Controller to resolve destination VM MAC.
-/etc/init.d/netcpad status ( to check if Netcpa is running)
-esxcli network ip connection list | grep 1234 ( to check if connection is established to all controllers)
2.i would check if the hosts have installed successfully the vxlan in question.
-esxcli network vswitch dvs vmware vxlan network list –vds-name dvs-rem
the next steps depends really on the above tests
Thanks for your reply, Hatim! Those are all excellent suggestions and very logical next steps. I won’t say more now so as not to spoil the solution for anyone 🙂
I will have the full solution posted in a few days.
Sounds like it’s not added to the universal transport zone at the remote data center location. Ensure it’s added to under Logical Network Preparation -> Transport Zones