Welcome to the tenth installment of a new series of NSX troubleshooting scenarios. Thanks to everyone who took the time to comment on the first half of the scenario. Today I’ll be performing some troubleshooting and will show how I came to the solution.
Please see the first half for more detail on the problem symptoms and some scoping.
Getting Started
As we saw in the first half, our fictional administrator was attempting to configure an ESG load balancer for both TCP and UDP port 514 traffic. Below is the high-level topology:
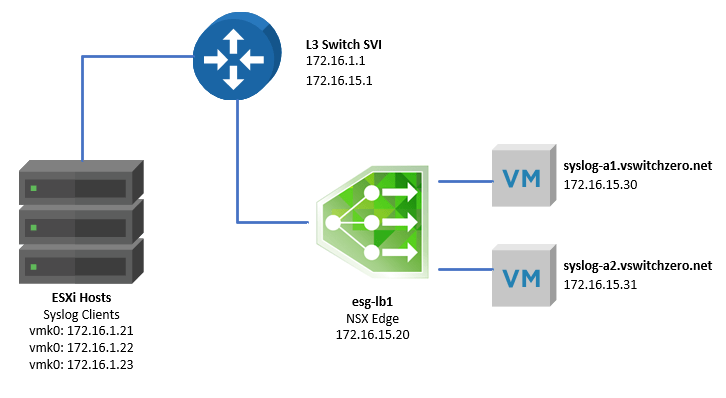
One of the first things to keep in mind when troubleshooting the NSX load balancer is the mode in which it’s operating. In this case, we know the customer is using a one-armed load balancer. The tell-tale sign is that the ESG sits in the same VLAN as the pool members with a single interface. Also, the pool members do not have the ESG configured as their default gateway.
We also know based on the screenshots in the first half that the load balancer is not operating in ‘Transparent’ mode – so traffic to the pool members should appear as though it’s coming from the load balancer virtual IP, not from the actual syslog clients. The packet capture the customer did proves that this is actually not the case.
That said, how exactly does an NSX one-armed load balancer work?
As traffic comes in on one of the interfaces and ports configured as a ‘virtual server’, the load balancer will simply forward the traffic to one of the pool members based on the load balancing algorithm configured. In our case, it’s a simple ‘round robin’ rotation of the pool members per session/socket. But forwarding would imply that the syslog servers would see traffic coming from the originating source IP of the syslog client. This would cause a fundamental problem with asymmetry when the pool member needs to reply. When it does, the traffic would bypass the ESG and be sent directly back to the client. This would be fine with UDP, which is connection-less, but what about TCP?
In a TCP based flow, this could not work. Each TCP socket is comprised of a source IP and port and a destination IP and port. If a syslog client tries to establish a TCP connection – using a SYN segment – to the ESG load balancer VIP, it expects the SYN-ACK to come from the same IP. What if it comes from a different IP, like that of one of the pool members? As far as TCP is concerned, that’s a SYN-ACK from an IP it has nothing to do with – it’ll immediately send a reset. The three-way handshake will never be established.
This sounds an awful lot like what our fictional customer is reporting.
NAT and the ESG Firewall
The load balancer needs a way to change the source IP of the traffic headed to the pool member. If it forwards the TCP segment to the pool member with a source IP of itself, the pool member will reply directly to the load balancer – not the client. This allows the load balancer ESG to then forward the reply back to the syslog client, again changing the source IP to itself instead of the pool member. This simple masquerading allows the load balancer to force all ingress and egress to/from the pool members through itself without needing to rely on routing. This is the key benefit of a one-armed load balancer.
So how does the ESG do this? Simple – using NAT.
When the load balancer is configured, some internal NAT rules are created for this IP address translation. Below you can see two internal DNAT rules with a very telling warning banner above:
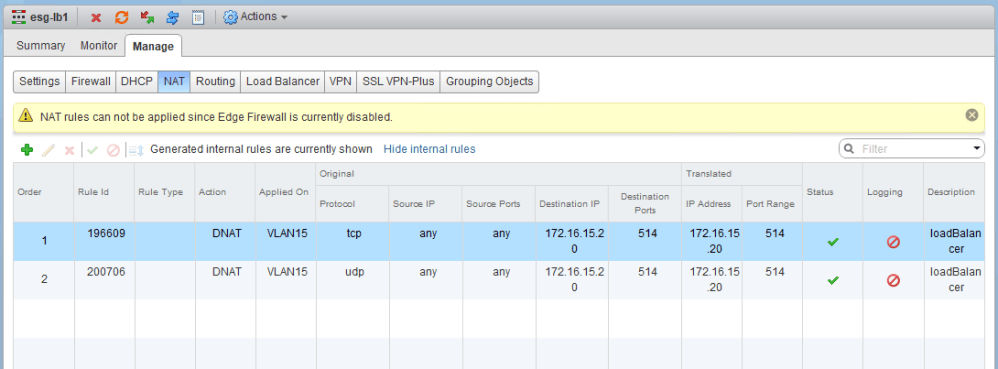
The DNAT rules that are visible in the UI don’t make much sense, because they just translate the destination VIP address to itself again on the same port. Behind the scenes, it’s doing SNAT and DNAT for the necessary IP translations for the load balancer to function. To validate the internal DNAT/SNAT rules, you can do a ‘show nat’ from the ESG command line. The SNAT ‘masquerade’ rules of interest will be listed in the int_snat chain:
esg-lb1.vswitchzero.net-0> show nat ++++++++++++++++ IPv4 rules/flows ++++++++++++++++ <snip> Chain int_dnat (2 references) rid pkts bytes target prot opt in out source destination Chain int_snat (1 references) rid pkts bytes target prot opt in out source destination 0 0 0 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 policy match dir out pol ipsec mode tunnel 0 1 202 MASQUERADE all -- * * 0.0.0.0/0 0.0.0.0/0 vaddr 172.16.15.20 vport 514 0 0 0 MASQUERADE all -- * * 0.0.0.0/0 0.0.0.0/0 vaddr 172.16.15.20 vport 514 Chain usr_dnat (2 references) rid pkts bytes target prot opt in out source destination 0 0 0 DNAT tcp -- vNic_0 * 0.0.0.0/0 172.16.15.20 multiport dports 514 to:172.16.15.20:514 0 1 202 DNAT udp -- vNic_0 * 0.0.0.0/0 172.16.15.20 multiport dports 514 to:172.16.15.20:514
The important thing to remember here is that the load balancer requires NAT to function, and for NAT to function, the ESG firewall must be enabled. As we saw in the first half, the customer disabled the ESG firewall:
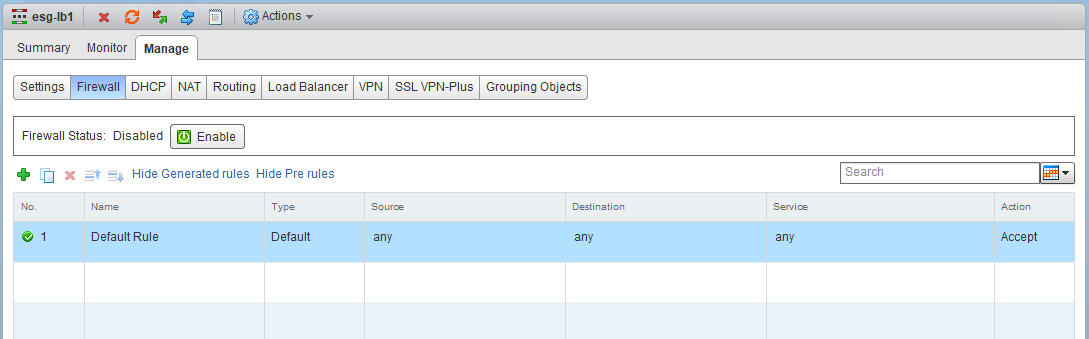
After enabling the firewall, we can see that TCP traffic begins to flow through the load balancer, as does UDP. Notice that the source IP of all UDP traffic arriving at syslog-a1 is now sourced from 172.16.15.20 – the load balancer VIP.
23:42:02.663113 IP 172.16.15.20.45575 > syslog-a1.vswitchzero.net.syslog: SYSLOG local4.debug, length: 163 23:42:02.721381 IP 172.16.15.20.45575 > syslog-a1.vswitchzero.net.syslog: SYSLOG local4.debug, length: 165 23:42:02.721394 IP 172.16.15.20.45575 > syslog-a1.vswitchzero.net.syslog: SYSLOG local4.debug, length: 173 23:42:02.725583 IP 172.16.15.20.45575 > syslog-a1.vswitchzero.net.syslog: SYSLOG local4.debug, length: 162 23:42:02.725625 IP 172.16.15.20.45575 > syslog-a1.vswitchzero.net.syslog: SYSLOG local4.debug, length: 170 23:42:02.725663 IP 172.16.15.20.45575 > syslog-a1.vswitchzero.net.syslog: SYSLOG local4.debug, length: 170 23:42:02.725690 IP 172.16.15.20.45575 > syslog-a1.vswitchzero.net.syslog: SYSLOG local4.debug, length: 163
Q&A
Here are the answers to some questions posed in the first half:
Q: What does enabling/disabling acceleration mean in the context of the NSX load balancer?
A: ‘Acceleration’ being enabled simply means that the internal load balancer service is operating in L4 mode only, not L7. This limits what can be inspected and acted upon by the load balancer, but can greatly improve performance. For basic TCP/UDP flows, L4 mode is usually sufficient. If application layer headers – like HTTP/HTTPS for example – needed to be inspected, L7 is required. For UDP, acceleration must be enabled.
Q: Why are two virtual servers defined here?
A: This customer has defined two virtual servers using the same virtual IP (VIP). One exists for incoming TCP on port 514, and the other for UDP on port 514. Although port ranges can be configured, you cannot have TCP and UDP defined in a single virtual server, which is why two exist here.
Q: What is the difference between the ‘Monitor Port’ and the ‘Port’ defined in the pool configuration?
A: The monitor port is used by the service monitor for health checks. For example, the default TCP monitor will do a simple check to ensure the pool member is listening on the configured port. This information is used to determine if the member is up or down and is mandatory.
You may have noticed that the ‘Port’ field was left blank. Despite looking like an omission, it’s perfectly fine. If left blank, whatever port the incoming traffic uses will also be used for forwarding on to pool members. I.e. if syslog TCP 514 is received, it’ll be forwarded to pool members at TCP 514 as well. If you wanted to redirect TCP 514 to TCP 1514 for example, you could specify a different value here.
Q: This scenario uses a ‘one armed’ load balancer configuration. How does a one armed load balancer work and how does it differ from an in-line configuration?
A: There are essentially two types – one-armed and inline. The single most defining difference between these two modes is whether or not the load balanced pool needs to route through the ESG to function. I.e. the pool members use the ESG load balancer as their default gateway. You can find more information on this in the previous section of this post, as well as the VMware blog here.
Q: What is odd about the packet capture? Why shouldn’t the traffic be shown as originating from the ESXi hosts?
A: Please see the previous section. This was answered in detail earlier in the post.
Q: What configuration is required for the load balancer to work in this mode? Could something be missing here?
A: The ESG firewall was disabled. Because the load balancer depends on NAT to function, the firewall must be enabled. More detail on this can be found earlier on in the post.
Reader Comments
Thanks to everyone who took the time to comment. James (@0x86DD) was right on the money about SNAT:
https://twitter.com/0x86DD/status/1004645235027308544
Conclusion
And there you have it – a simple fix. As long as you know how the load balancer functions, the problem becomes clear.
Please feel free to leave a comment below or reach out to me on Twitter (@vswitchzero)

Hi Mike,
Many thanks for these great troubleshooting scenarios — they really help me to understand NSX.
I have a question: “Why is an internal DNAT rule rule created in the iptables NAT table on an NSX edge when a L7 LB VIP is created?”
So, a similar scenario to the one you describe here but the VIP is not accelerated so the LB is HAproxy.
In testing such a configuration in a lab I got a root prompt to the NSX edge and deleted the internal DNAT rule using (using iptables command). The LB worked fine after that deletion. I then flushed all the iptables NAT table rules completely. The LB worked fine again. I assume the appropriate NATing is being done in the HAProxy process. In which case what is the reason for the internal DNAT rule?
Cheers
Simon