Welcome to the tenth installment of a new series of NSX troubleshooting scenarios. Thanks to everyone who took the time to comment on the first half of the scenario. Today I’ll be performing some troubleshooting and will show how I came to the solution.
Please see the first half for more detail on the problem symptoms and some scoping.
Getting Started
As we saw in the first half, our fictional administrator was attempting to configure an ESG load balancer for both TCP and UDP port 514 traffic. Below is the high-level topology:
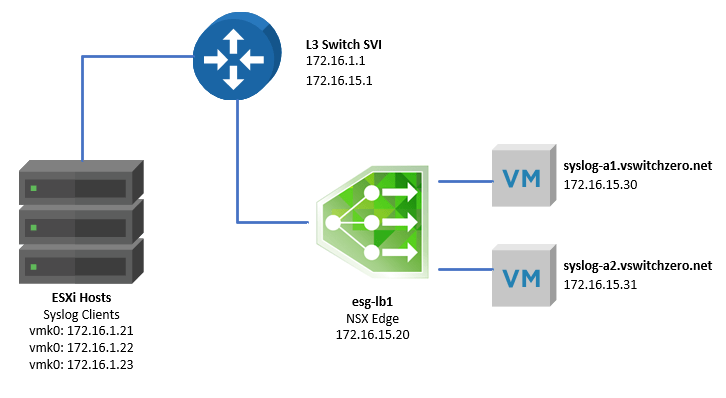
One of the first things to keep in mind when troubleshooting the NSX load balancer is the mode in which it’s operating. In this case, we know the customer is using a one-armed load balancer. The tell-tale sign is that the ESG sits in the same VLAN as the pool members with a single interface. Also, the pool members do not have the ESG configured as their default gateway.
We also know based on the screenshots in the first half that the load balancer is not operating in ‘Transparent’ mode – so traffic to the pool members should appear as though it’s coming from the load balancer virtual IP, not from the actual syslog clients. The packet capture the customer did proves that this is actually not the case.
That said, how exactly does an NSX one-armed load balancer work?
As traffic comes in on one of the interfaces and ports configured as a ‘virtual server’, the load balancer will simply forward the traffic to one of the pool members based on the load balancing algorithm configured. In our case, it’s a simple ‘round robin’ rotation of the pool members per session/socket. But forwarding would imply that the syslog servers would see traffic coming from the originating source IP of the syslog client. This would cause a fundamental problem with asymmetry when the pool member needs to reply. When it does, the traffic would bypass the ESG and be sent directly back to the client. This would be fine with UDP, which is connection-less, but what about TCP?
Continue reading “NSX Troubleshooting Scenario 10 – Solution”
