Welcome to the eleventh installment of a new series of NSX troubleshooting scenarios. Thanks to everyone who took the time to comment on the first half of the scenario. Today I’ll be performing some troubleshooting and will show how I came to the solution.
Please see the first half for more detail on the problem symptoms and some scoping.
Getting Started
As you’ll recall in the first half, our fictional customer was seeing some HA heartbeat channel alarms in the new HTML5 NSX dashboard.
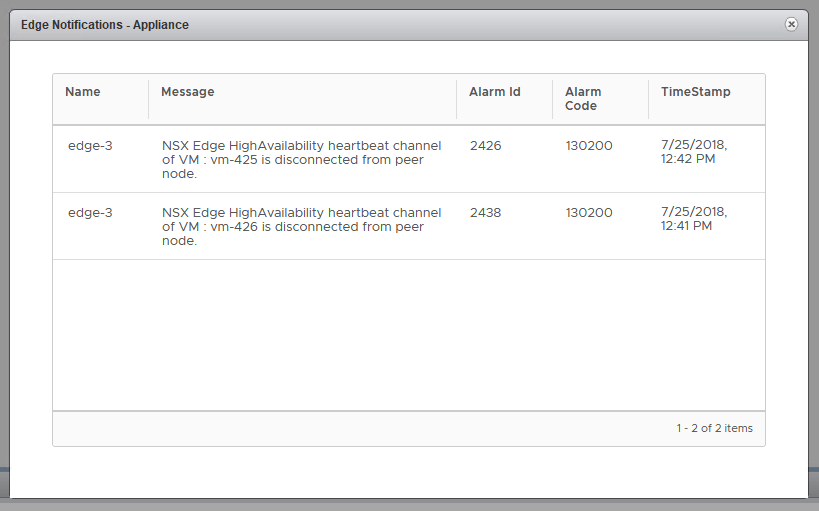
After doing some digging, we were able to determine that the ESG had an interface configured for HA on VLAN 16 and that from the CLI, the edge really was complaining about being unable to reach its peer.
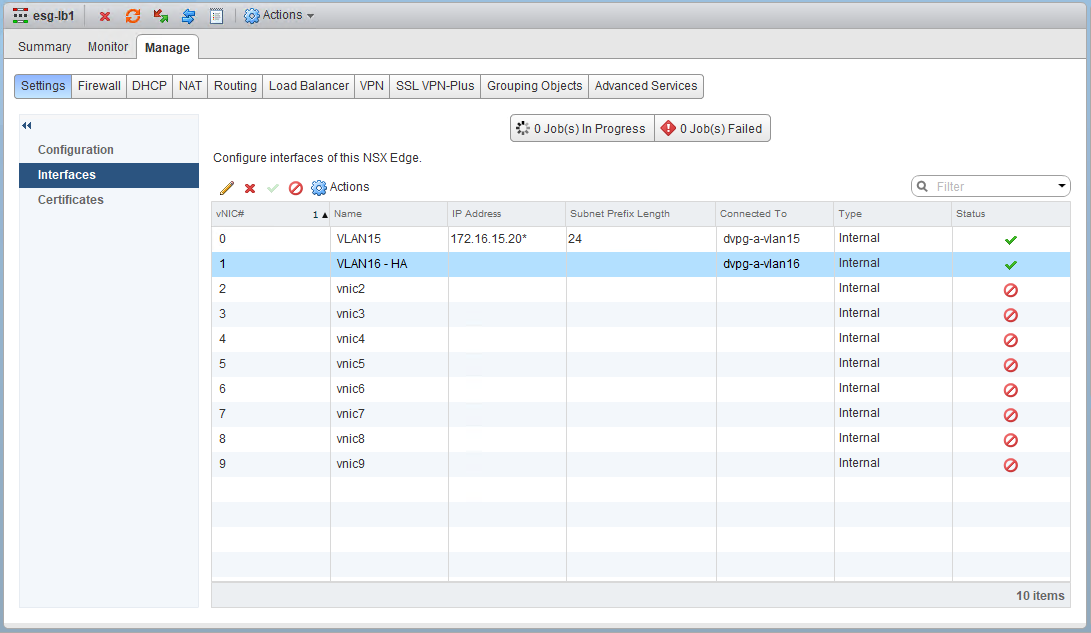
You probably noticed in the first half, that the HA interface doesn’t have an IP address configured. This may look odd, but it’s fine. Even if you did specify a custom /30 IP address for HA purposes, it would not show up as an interface IP address here. Rather, you’d need to look for one specified in the HA configuration settings here:
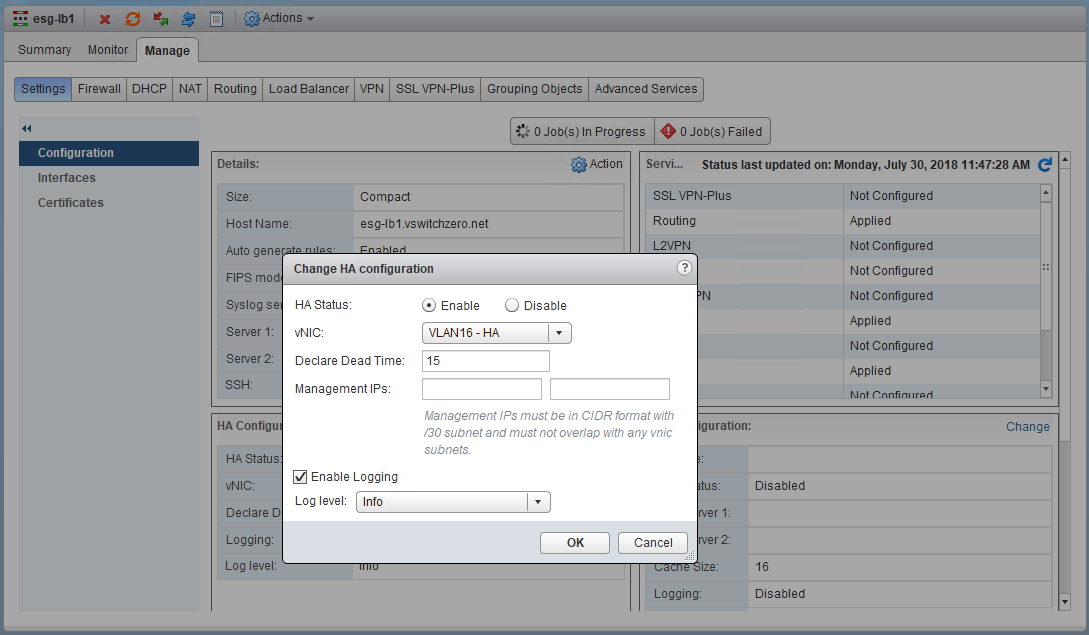
In this case, there aren’t any so NSX uses the default, which are 169.254.x.x APIPA addresses. Many people associate APIPA (Automatic Private IP Addressing) with devices unable to get DHCP addresses and will quite often assume this means there are connectivity problems. When it comes to NSX HA, this is normal and expected.
Logging into the active HA node, we can see that a /30 APIPA subnet is present in the routing table:
esg-lb1.vswitchzero.net-1> sh ip forwarding Codes: C - connected, R - remote, > - selected route, * - FIB route R>* 0.0.0.0/0 via 172.16.15.1, vNic_0 C>* 169.254.1.0/30 is directly connected, vNic_1 C>* 172.16.15.0/24 is directly connected, vNic_0
We can also see that the IP assigned to the vNIC1 HA interface is 169.254.1.2:
esg-lb1.vswitchzero.net-1> sh int vNic_1 vNic_1 Link encap:Ethernet HWaddr 00:50:56:AA:09:B0 inet addr:169.254.1.2 Bcast:169.254.1.3 Mask:255.255.255.252 inet6 addr: fe80::250:56ff:feaa:9b0/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:2 errors:0 dropped:0 overruns:0 frame:0 TX packets:16900 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:120 (120.0 b) TX bytes:1252328 (1.1 Mb)
Because each ESG is assigned a /30 APIPA subnet by NSX Manager, we know that this appliance’s peer must be 169.254.1.1. Each /30 has only have two usable IP addresses as the first and last in this four address subnet are for network and broadcast.
esg-lb1.vswitchzero.net-1> esg-lb1.vswitchzero.net-1> ping 169.254.1.1 PING 169.254.1.1 (169.254.1.1) 56(84) bytes of data. --- 169.254.1.1 ping statistics --- 4 packets transmitted, 0 received, 100% packet loss, time 2999ms
Sure enough, we can’t ping the peer appliance. It seems pretty clear that we are dealing with a communication issue on VLAN 16 between these two appliances.
Narrowing Down
Because the appliances are communicating via a VLAN backed portgroup, let’s see what hosts they are currently registered on.
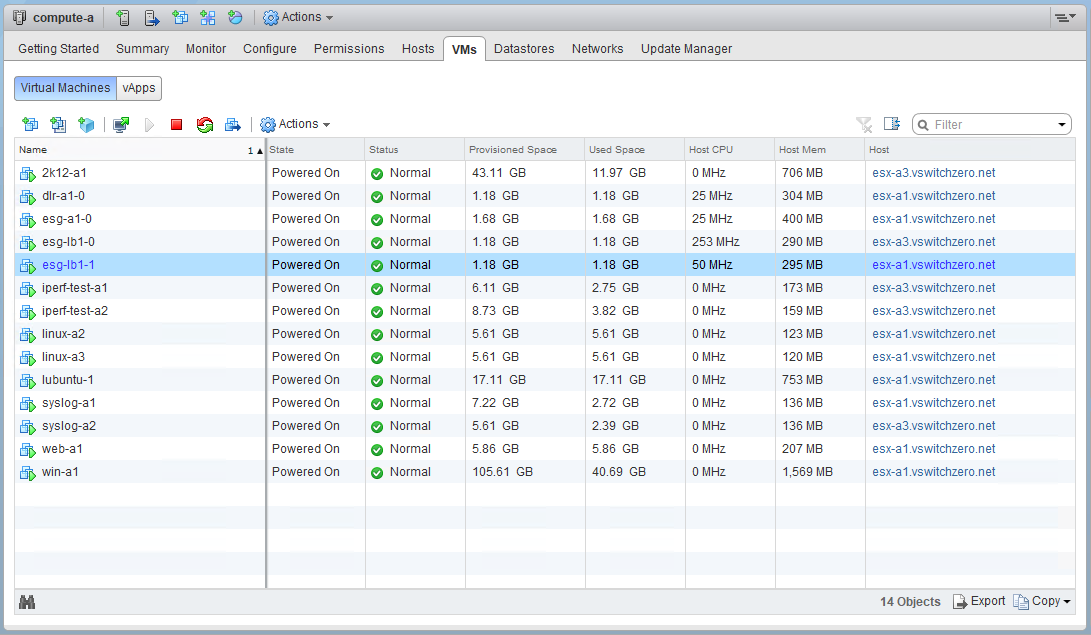
As of right now, the active node is on esx-a1, and the passive node is on esx-a3. Now, a really quick test we can do to eliminate any guest-level problems is to move both appliances onto the same host. Because their HA interfaces are both in the same porgroup and same subnet, the two appliances will be communicating completely in software – there would be no physical networking to deal with at all.
After moving them both onto host esx-a1, we are now able to ping just fine:
esg-lb1.vswitchzero.net-1> ping 169.254.1.1 PING 169.254.1.1 (169.254.1.1) 56(84) bytes of data. 64 bytes from 169.254.1.1: icmp_seq=1 ttl=64 time=0.413 ms 64 bytes from 169.254.1.1: icmp_seq=2 ttl=64 time=0.407 ms 64 bytes from 169.254.1.1: icmp_seq=3 ttl=64 time=0.382 ms
Looking at the HA status, we can also see that the two nodes are heartbeating successfully once again:
esg-lb1.vswitchzero.net-1> sh service highavailability Highavailability Service: Highavailability Status: Active Highavailability State since: 2018-07-30 13:35:22.399 Highavailability Unit Id: 1 Highavailability Unit State: Up Highavailability Admin State: Up Highavailability Running Nodes: 0, 1 Unit Poll Policy: Frequency: 3.75 seconds Deadtime: 15 seconds Highavailability Services Status: Healthcheck Config Channel: Up Healthcheck Status Channel: Up Highavailability Healthcheck Status: Peer unit [0]: Up Active: 0 Session via vNic_1: 169.254.1.2:169.254.1.1 Up This unit [1]: Up Active: 1 <snip>
What this proves is that when we eliminate the physical networking from the equation, they communicate just fine on VLAN 16. Separate them on host esx-a1 and esx-a3, and they stop working.
In the first half of the scenario, you may have noticed that host esx-a3 was reporting an alarm. Let’s have a closer look:
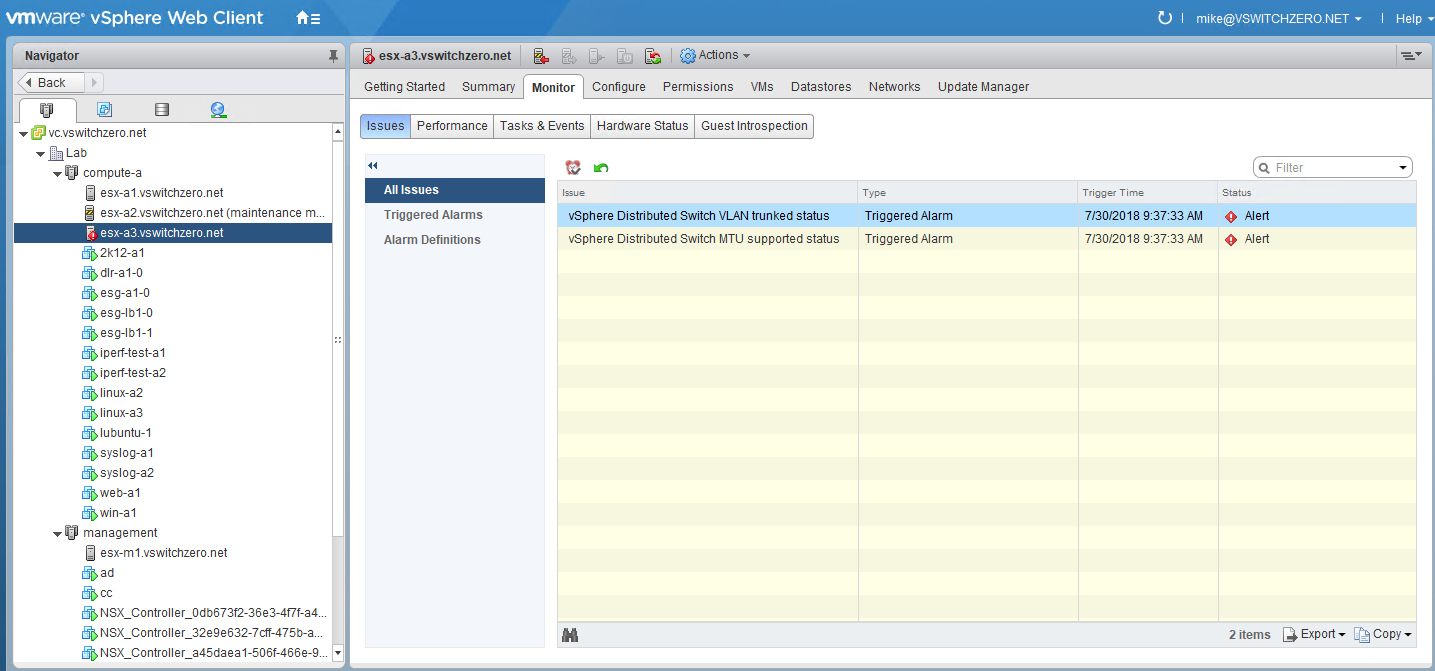
Drilling down into the ‘All Issues’ view, we can see that this host is reporting a VLAN/MTU health check problem. This could certainly be something relevant, since we know the appliances can’t communicate on VLAN 16 between host esx-a1 and esx-a3. Perhaps there is a VLAN misconfigured on the physical switch connecting to host esx-a3?
Physical Network Checks
We’ll need to check the physical switch configuration to see if esx-a3 is configured consistently with esx-a1 and esx-a2. To begin, we’ll need to determine what physical ports are associated with the two vmnics on this host.
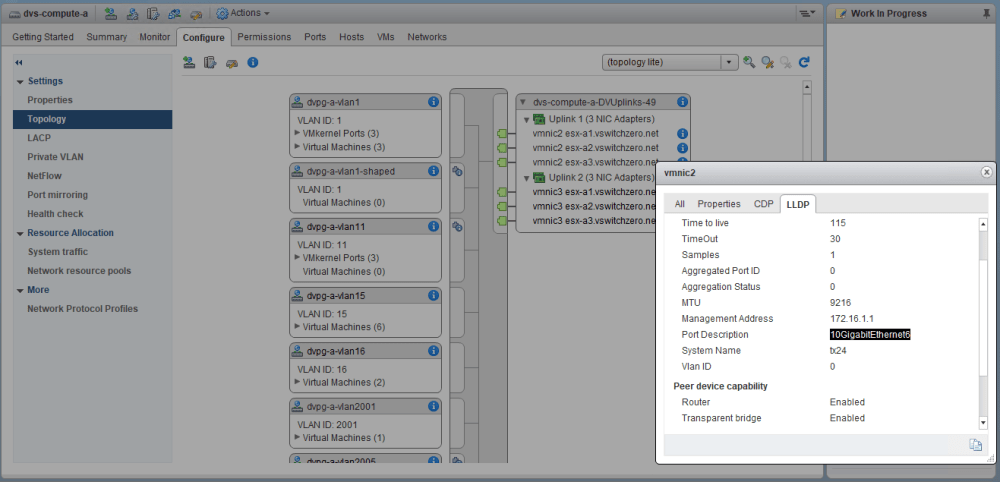
Thankfully, LLDP is enabled on this switch, so we can get the port numbers this way. On a switch with management IP 172.16.1.1, the ports in question are Ethernet 5 and Ethernet 6.
A quick note about the VLAN ID reported in CDP/LLDP – this value here is only ever useful if we’re dealing with access ports in a single VLAN. Whenever a port is trunked, this reported value is not useful. It generally corresponds only to the native VLAN/PVID on trunk ports. Since we have a value of 0 reported here, I’d guess that this interface only allows 802.1q trunked VLANs.
Looking at the switch itself, we can see that the interface labels also seem to match. Ports 5 and 6 belong to esx-a3.
switch#sh int br Port Link State Dupl Speed Trunk Tag Pvid Pri MAC Name 1 Up Forward Full 10G None Yes N/A 0 54ab.3a41.d312 esx-a1-1 2 Up Forward Full 10G None Yes N/A 0 54ab.3a41.d312 esx-a1-2 3 Up Forward Full 10G None Yes N/A 0 54ab.3a41.d312 esx-a2-1 4 Up Forward Full 10G None Yes N/A 0 54ab.3a41.d312 esx-a2-2 5 Up Forward Full 10G None Yes N/A 0 54ab.3a41.d312 esx-a3-1 6 Up Forward Full 10G None Yes N/A 0 54ab.3a41.d312 esx-a3-2 7 Up Forward Full 10G None Yes N/A 0 54ab.3a41.d312 esx-m1-v 8 Up Forward Full 10G None Yes N/A 0 54ab.3a41.d312 esx-m1-v
Checking the port members for VLAN 16, we can see that only ports 1 to 4 are tagged. The two interfaces associated with esx-a3 are not members at all.
switch#sh vlan 16 Total PORT-VLAN entries: 9 Maximum PORT-VLAN entries: 64 PORT-VLAN 16, Name Lab_HB1, Priority level0, Spanning tree Off Untagged Ports: None Tagged Ports: 1 2 3 4 Uplink Ports: None DualMode Ports: None
This explains why things worked when host esx-a2 was online – it’s likely that the two HA nodes were on hosts esx-a1 and esx-a2 previously, and when esx-a2 went into maintenance mode, one of the nodes moved to esx-a3.
After adding ports 5 and 6 to VLAN 16 as tagged members, the two HA nodes were successfully communicating with each other again.
Split Brain?
One interesting point our fictional customer raises is:
“…I think this may be a false alarm, because the two appliances are in the correct active and standby roles and not in split-brain. Why is this happening?”
And he definitely would have been correct in the past. In older versions, like 6.2.x, if the two appliances stopped communicating via heartbeats but both were still up, the passive node would have tried to assume the active role. While this is happening, the active node would remain active because it has no idea what happened to the passive node. This type of situation where both appliances become active is referred to as ‘Split-Brain’.
You can probably imagine the chaos that ensues when this happens. Not only do both appliances attempt to use the same interface IP addresses, causing conflicts, but the state of many services and firewall connection tracking gets out-of-sync. In the case of DLR appliances, dynamic routing and communication to/from the control plane is impacted as well. Needless to say, HA split-brain can sometimes cause more harm than the outages HA looks to protect against.
In 6.4.x, VMware made many HA improvements. NSX manager now acts as a ‘witness node’ of sorts – monitoring the HA state of both appliances via the internal VMCI channel it has with them. If it sees that both appliances are up, and they can’t communicate with each other via heartbeats, it can force one node to assume the standby role. If a node genuinely goes down because of a host crash or some other catastrophic failure, NSX Manager will know – and that VMCI communication channel will also be severed. In this case, a Standby node can assume the Active role if necessary.
Based on what happened in this customer’s situation – with only the HA heartbeat network being impacted – NSX manager intervened and prevented a split-brain situation. The sequence of events was likely something like this:
- Host esx-a2 was evacuated and put into maintenance mode.
- The esg-lb1-0 node moved from host esx-a2 to esx-a3.
- HA heartbeats on VLAN 16 were no longer reaching each node.
- Each node began to increment their dead timers.
- After 15 seconds, the passive node is ready to assume the active role.
- NSX Manager sees that both nodes are still alive via the VMCI channel. NSX Manager runs a script on the ESGs to force one of them to remain passive until the heartbeats begin flowing again.
It’s very fortunate that this customer was running 6.4.0. Had they been running an older release, this would have almost certainly resulted in an outage.
Conclusion
And there you have it – a simple switch configuration problem. Please feel free to leave a comment below or reach out to me on Twitter (@vswitchzero)
