Welcome to the eleventh installment of my NSX troubleshooting series. What I hope to do in these posts is share some of the common issues I run across from day to day. Each scenario will be a two-part post. The first will be an outline of the symptoms and problem statement along with bits of information from the environment. The second will be the solution, including the troubleshooting and investigation I did to get there.
The Scenario
As always, we’ll start with a brief problem statement:
“One of my ESXi hosts has a hardware problem. Ever since putting it into maintenance mode, I’m getting edge high availability alarms in the NSX dashboard. I think this may be a false alarm, because the two appliances are in the correct active and standby roles and not in split-brain. Why is this happening?”
A good question. This customer is using NSX 6.4.0, so the new HTML5 dashboard is what they are referring to here. Let’s see the dashboard alarms first hand.
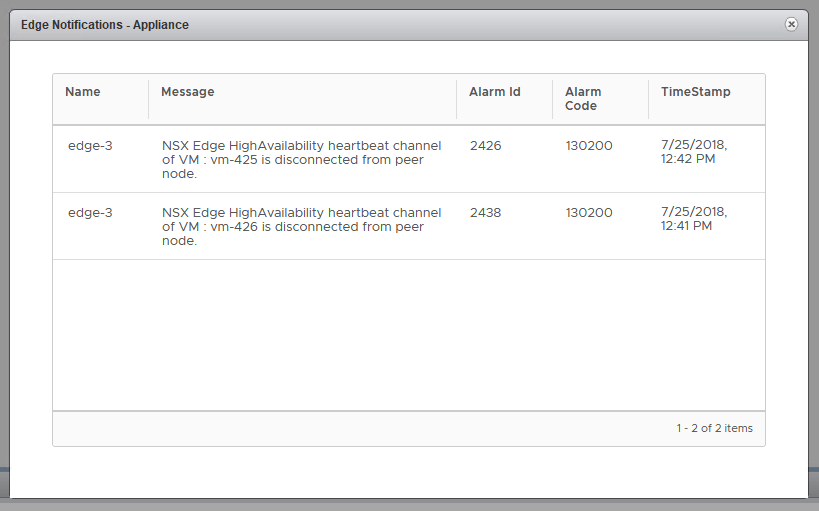
This is alarm code 130200, which indicates a failed HA heartbeat channel. This simply means that the two ESGs can’t talk to each other on the HA interface that was specified. Let’s have a look at edge-3, which is the ESG in question.
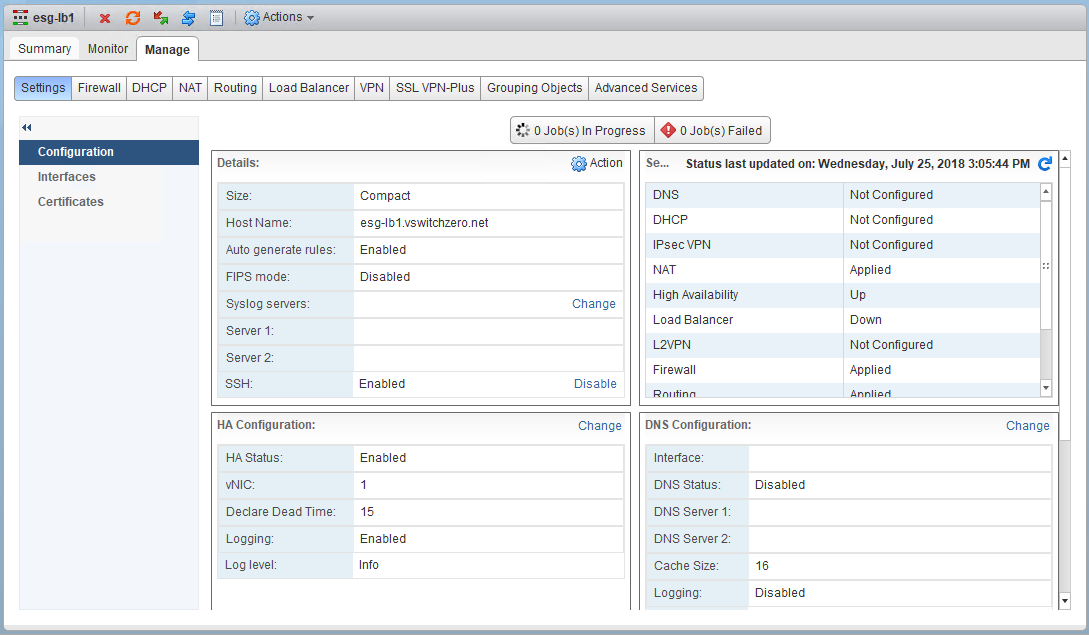
HA is configured and enabled. We can see that it’s currently set to use vNIC interface 1 on the edge. Let’s see where this interface connects:
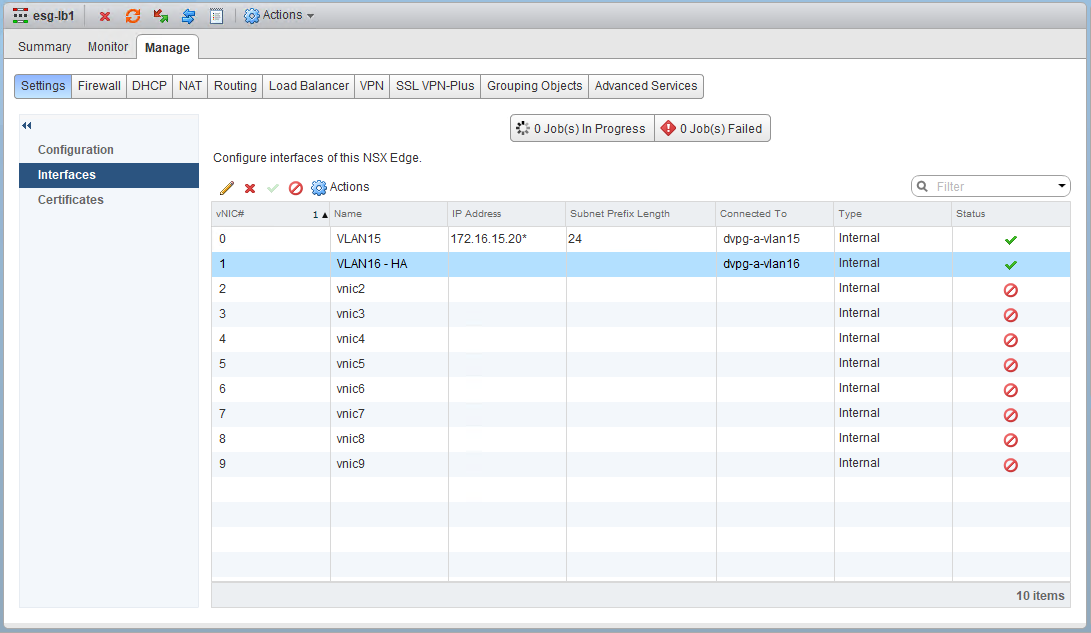
It’s a VLAN backed dvPortgroup called dvpg-a-vlan16. The interface is enabled, but there isn’t an IP address or subnet prefix defined here. It doesn’t look like this interface is used for any purpose other than HA on this ESG.
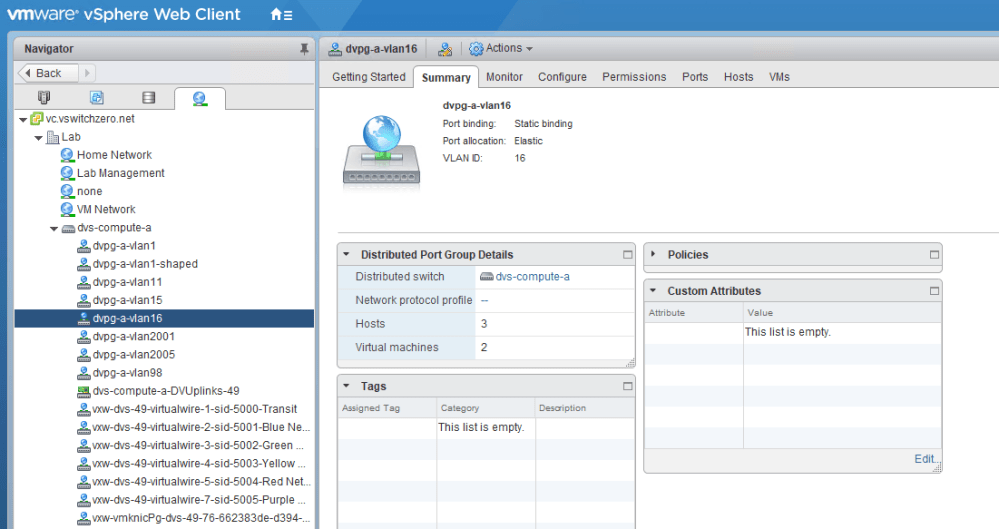
All three hosts are connected to the dvs-compute-a distributed switch. We can see that the VLAN ID is 16 here as expected.
With host esx-a2 in maintenance mode due to hardware problems, the two ESGs are separated on host esx-a1 and esx-a3 as would be expected.
Logging into the ESG via SSH, we can see that it’s the esg-lb1-1 appliance that appears to be in the active role. It is indeed reporting that its peer is unreachable:
esg-lb1.vswitchzero.net-1> sh service highavailability
Highavailability Service:
Highavailability Status: Active
Highavailability State since: 2018-07-25 16:41:49.478
Highavailability Unit Id: 1
Highavailability Unit State: Up
Highavailability Admin State: Up
Highavailability Running Nodes: 1
Unit Poll Policy:
Frequency: 3.75 seconds
Deadtime: 15 seconds
Highavailability Services Status:
Healthcheck Config Channel: Up
Healthcheck Status Channel: Up
Highavailability Healthcheck Status:
Peer unit [0]: Unreachable Active: 0
Session via vNic_1: 169.254.1.2:169.254.1.1 Unreachable
This unit [1]: Up Active: 1
Config Engine:
HA Configuration: Enabled
HA Admin State: Up
Config Engine Status: Active
ForceStandby Flag: Disabled
Highavailability Stateful Logical Status:
File-Sync running
Connection-Sync running
xmit xerr rcv rerr
463052 0 0 0
We’ll also confirm the customer’s statement about split brain here. Let’s ensure the other appliance is in the Standby role:
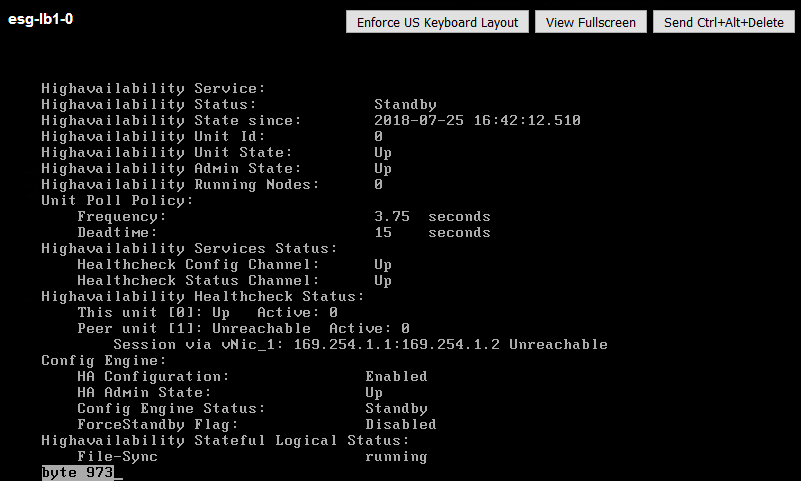
Sure enough, it is. Despite reporting that it can’t reach it’s peer, the two appliances are still maintaining the appropriate roles.
What’s Next
I’ll post the solution in the next day or two, but what could explain this behavior? Why are the appliances not in split-brain and disagreeing about their roles?
How would you handle this scenario? Let me know! Please feel free to leave a comment below or via Twitter (@vswitchzero).
