Welcome to the fourteenth installment of my NSX troubleshooting series. What I hope to do in these posts is share some of the common issues I run across from day to day. Each scenario will be a two-part post. The first will be an outline of the symptoms and problem statement along with bits of information from the environment. The second will be the solution, including the troubleshooting and investigation I did to get there.
The Scenario
As always, we’ll start with a brief problem statement:
“I’m trying to prevent some specific BGP routes from being advertised to my DLR, but the route filters aren’t working properly. Every time I try to do this, I get an outage to everything behind the DLR!”
Let’s have a quick look at what this fictional customer is trying to do with BGP.

The design is simple – a single ESG peered with a single DLR appliance. The /21 address space assigned to this environment has been split out into eight /24 networks.
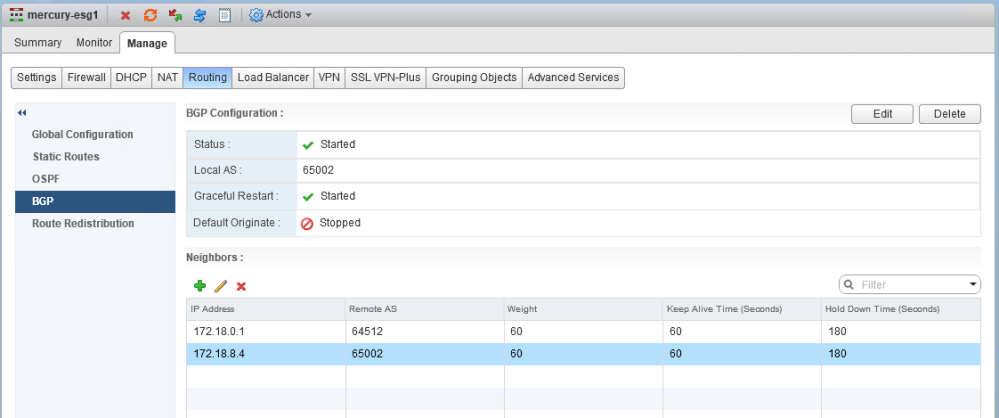
The mercury-esg1 appliance has two neighbors configured – the physical router (172.18.0.1) and the southbound DLR protocol address (172.18.8.4). Both the ESG and DLR are in the same AS (iBGP).
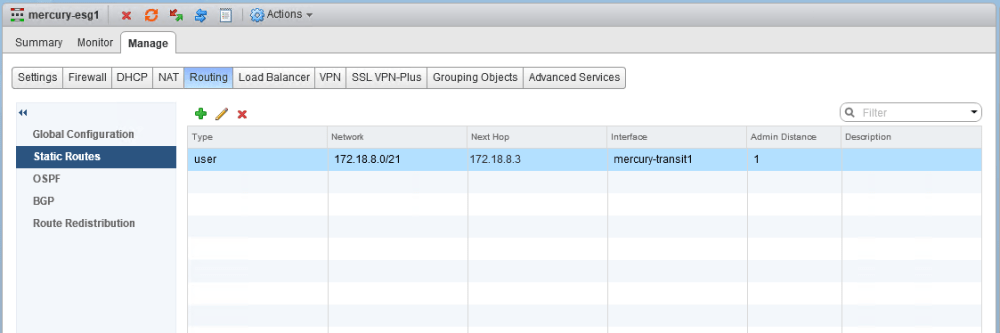
As you can see, on mercury-esg1 a summary static route has been created with the DLR forwarding address as the next hop. This /21 summarizes all eight /24 subnets that will be assigned to the logical switches in this environment. Because the customer wants more specific /24 BGP routes to be advertised by the DLR, this is what is referred to as a floating static route. Because it’s less specific, it’ll only take effect as a backup should BGP peering go down. This is a common design consideration and provides a bit of extra insurance should the DLR appliance go down unexpectedly.
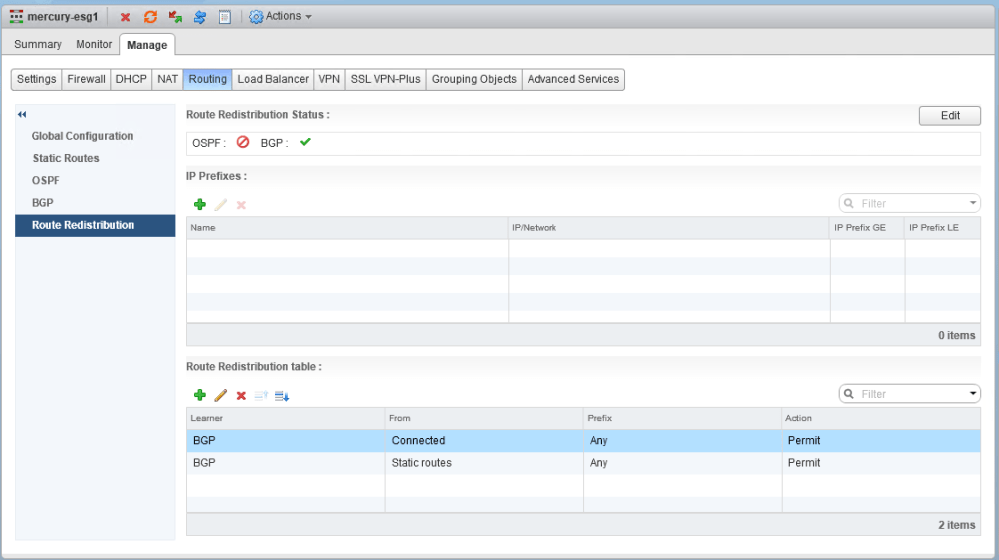
Redistribution of static routes into BGP has been configured, so by default, both the upstream physical router and the DLR will see this /21 prefix advertised by mercury-esg1. This is what the customer is trying to prevent using a BGP filter. Since this floating route is only useful to the upstream router, they want to prevent it from being redistributed to the DLR.
mercury-dlr.mercury.local-0> sh ip route Total number of routes: 16 Codes: O - OSPF derived, i - IS-IS derived, B - BGP derived, C - connected, S - static, L1 - IS-IS level-1, L2 - IS-IS level-2, IA - OSPF inter area, E1 - OSPF external type 1, E2 - OSPF external type 2, N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2 B 0.0.0.0/0 [200/0] via 172.18.8.1 B 10.61.0.0/24 [200/0] via 172.18.8.1 B 10.99.99.0/27 [200/0] via 172.18.8.1 B 172.16.1.0/24 [200/0] via 172.18.8.1 B 172.16.11.0/24 [200/0] via 172.18.8.1 B 172.16.15.0/24 [200/0] via 172.18.8.1 B 172.16.76.0/24 [200/0] via 172.18.8.1 B 172.17.0.0/27 [200/0] via 172.18.8.1 B 172.18.0.0/27 [200/0] via 172.18.8.1 B 172.18.8.0/21 [200/0] via 172.18.8.3 C 172.18.8.0/24 [0/0] via 172.18.8.4 C 172.18.9.0/24 [0/0] via 172.18.9.1 C 172.18.10.0/24 [0/0] via 172.18.10.1 C 172.18.11.0/24 [0/0] via 172.18.11.1 C 172.18.12.0/24 [0/0] via 172.18.12.1 B 192.168.1.0/24 [200/0] via 172.18.8.1
As you can see above in the DLR routing table, it doesn’t make sense to have a /21 for networks that are directly connected to the DLR. The connected routes will always exist for these /24 networks, so this summary will never be used. It can, however, cause some routing quirks with undefined networks included in this space – like 172.18.13.0/24, which doesn’t have a LIF yet.
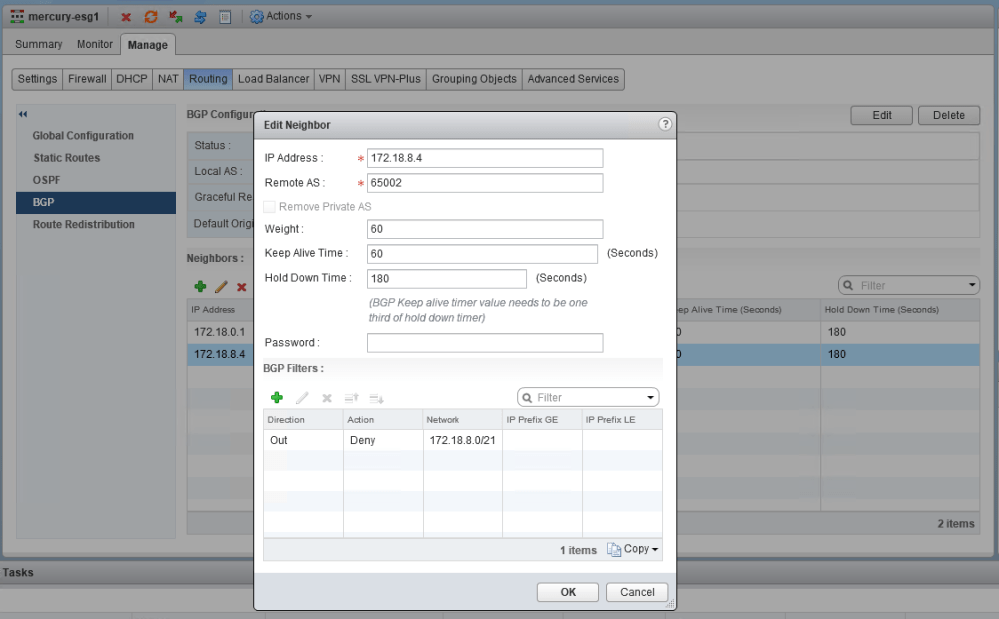
I’ve asked our fictional customer to reproduce the issue, so they’ve attempted to add the BGP filter again. This looks straight forward – For the neighbor 172.18.8.4 (DLR), deny the outbound advertisement of 172.18.8.0/21.
What immediately happens, however, is that all connectivity is lost to VMs behind this DLR. From a northbound jump box, we can’t ping any of the DLR LIF interfaces and can’t SSH into the DLR appliance.
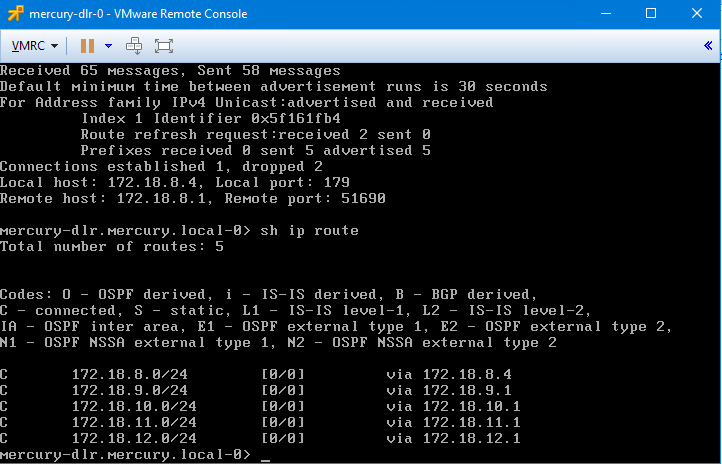
Consoling into the DLR, we can see why. All the BGP learned routes were removed from the DLR – even the default route. All we’ve got left are the five /24 connected networks. The BGP neighbor remains in the established state, but as soon as that BGP filter is removed, all connectivity is restored.
What’s Next
I’ll post the solution in the next day or two, but how would you handle this scenario? Let me know! Please feel free to leave a comment below or via Twitter (@vswitchzero).
