Welcome to the third instalment of a new series of NSX-T troubleshooting scenarios. Thanks to everyone who took the time to comment on the first half of the scenario. Today I’ll be performing some troubleshooting and will show how I came to the solution.
Please see the first half for more detail on the problem symptoms and some scoping.
Getting Started
As we saw in the first half, the customer’s management cluster was in a degraded state. This was due to one manager – 172.16.1.41 – being in a wonky half-broken state. Although we could ping it, we could not login and all of the services it was contributing to the NSX management cluster were down.
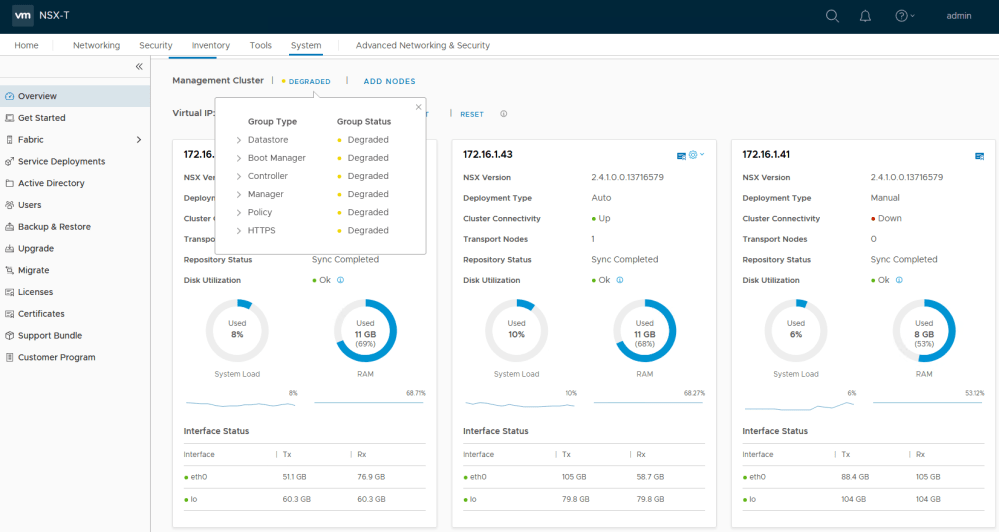
What was most telling, however, was the screenshot of the VM’s console window.
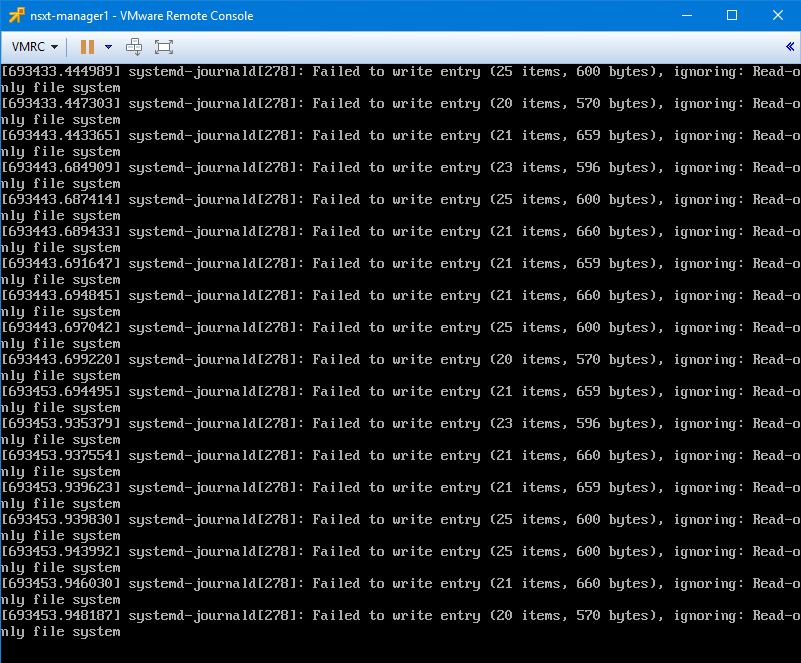
The most important keyword there was “Read-only file system”. As many readers had correctly guessed, this is a very common response to an underlying storage problem. Like most flavors of Linux, the Linux-based OS used in the NSX appliances will set their ext4 partitions to read-only in the event of a storage failure. This is a protective mechanism to prevent data corruption and further data loss.
When this happens, the guest may be partially functional, but anything that requires write access to the read-only partitions will obviously be in trouble. This is why we could ping the manager appliance, but all other functionality was broken. The manager cluster uses ZooKeeper for clustering services. ZooKeeper requires consistent and low-latency write access to disk. Because this wasn’t available to 172.16.1.41, it was marked as down in the cluster.
After discussing this with our fictional customer, we were able to confirm that an ESXi host esx-e3 experienced a total storage outage for a few minutes and that it had since been fixed. They had assumed it was not related because the appliance was on esx-e1, not esx-e3.
Recovering the Appliance
Thankfully, if the underlying storage is healthy again, recovering should be as simple as rebooting the appliance. In my case, I couldn’t log in or do a graceful shutdown via VMware Tools, so I did a cold ‘reset’ instead.
The VM came back up okay, and I was able to login successfully. Interestingly it was still in read-only mode after the reset. I suspect this is because the machine didn’t go down gracefully. You can see that root partition mount is still ‘ro’ and not ‘rw’ as we’d expect:
root@nsxt-manager1:~# mount
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime)
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
udev on /dev type devtmpfs (rw,nosuid,relatime,size=8191604k,nr_inodes=2047901,mode=755)
devpts on /dev/pts type devpts (rw,nosuid,noexec,relatime,gid=5,mode=620,ptmxmode=000)
tmpfs on /run type tmpfs (rw,nosuid,noexec,relatime,size=1641364k,mode=755)
/dev/sda2 on / type ext4 (ro,errors=remount-ro,data=ordered)
securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime)
tmpfs on /dev/shm type tmpfs (rw,nosuid,nodev)
Notice that the partition’s mount options include ‘errors=remount-ro’. This means that if it encounters I/O errors or can’t read from the filesystem for a defined period of time, it will remount the partition as read-only.
Rather than nuking the appliance, I decided to do a graceful reboot from the CLI. This time it booted up in ‘rw’ mode successfully.
root@nsxt-manager1:~# mount
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime)
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
udev on /dev type devtmpfs (rw,nosuid,relatime,size=8191604k,nr_inodes=2047901,mode=755)
devpts on /dev/pts type devpts (rw,nosuid,noexec,relatime,gid=5,mode=620,ptmxmode=000)
tmpfs on /run type tmpfs (rw,nosuid,noexec,relatime,size=1641364k,mode=755)
/dev/sda2 on / type ext4 (rw,errors=remount-ro,data=ordered)
securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime)
tmpfs on /dev/shm type tmpfs (rw,nosuid,nodev)
Within a few minutes of rebooting, the appliance synced up successfully and the cluster returned to a good state.
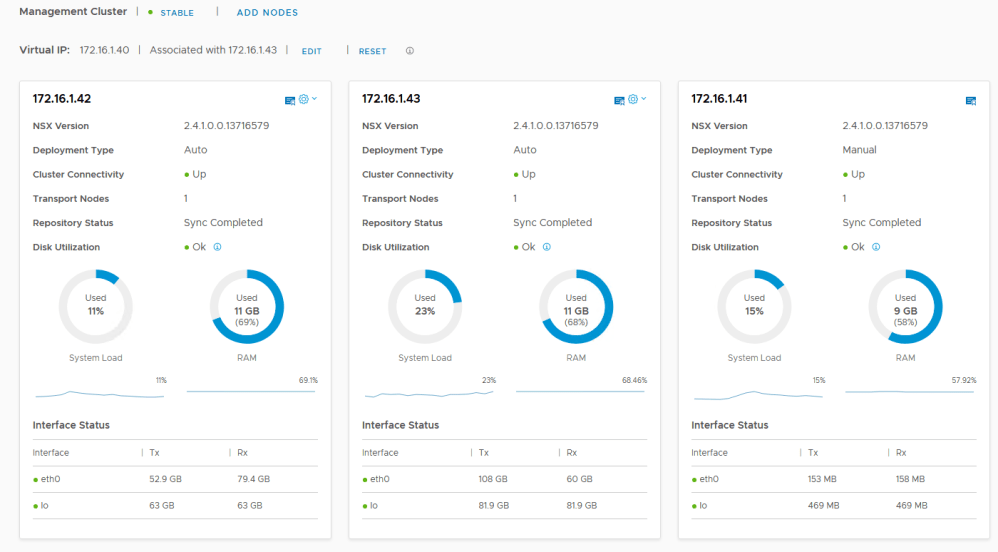
And just to satisfy my curiosity, we are able to confirm that this appliance definitely was on host esx-e3 previously, so the storage outage likely caused this:
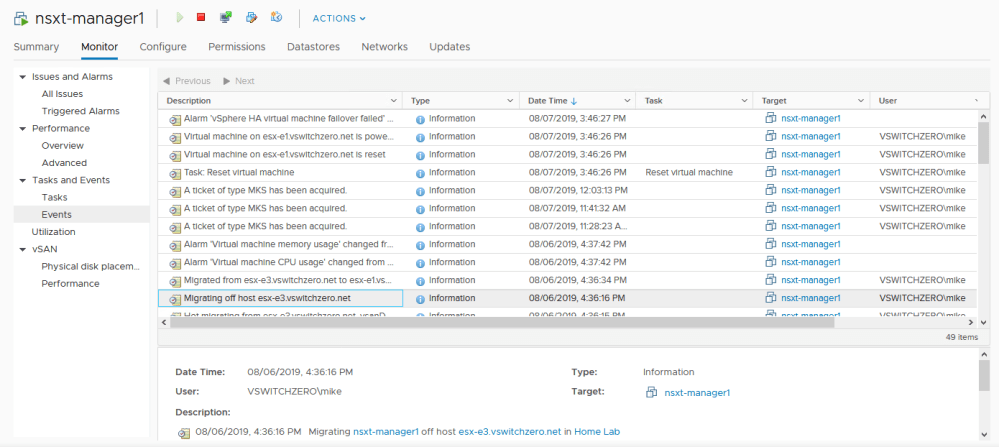
Although something like a brief loss of storage connectivity will usually mean that the appliance can be recovered, more serious outages – especially if data integrity is in question – may warrant more caution. Although it’s technically possible to attach the manager disk to another VM and run an fsck to correct errors, this is not supported nor recommended. These appliances are made to be disposable. If the appliance’s health is in question, it can be removed from the cluster, deleted from disk and then re-deployed and reattached. This is a post for another day.
Reader Feedback
Here is some reader feedback on scenario 3. Alexis has some good suggestions that would have worked:
James had a good question about checking the status from the working controllers to confirm. In this case the other two controllers reported 172.16.1.41 as down.
https://twitter.com/0x86DD/status/1159158599031107589?s=20
Harikrishnan mentions that the CorfuDB may be corrupted. Although it wasn’t corrupted, it definitely wasn’t functional.
Chris, who commented below was right on the money:
“Check storage on esx cluster. Fix where needed and reboot the server :> Read only file system can have multiple reasons. one of the is lost storage for a too long time. A reboot would help in that case.
– nfs storage maybe failed
– disk in datastore broken”
As was kayakbeachbar:
“First of all, I would open SR with VMware GSS
In parallel, I would do my own troubleshooting.
I see the message ” … Read-only file system” … on the console. I would try to understand why the file system is in read-only mode. Problem with underlying storage?”
Conclusion
This was a real situation I found myself in with my home lab. I had been testing some physical network card firmware options that caused esx-e3 to lose all connectivity to storage. Thanks to everyone who took the time to comment!

Thanks Mike, these scenarios will definitely help to improve applying troubleshooting skills in a wise and logical manner.