Welcome to the third instalment of a new series of NSX-T troubleshooting scenarios. Thanks to everyone who took the time to comment on the first half of the scenario. Today I’ll be performing some troubleshooting and will show how I came to the solution.
Please see the first half for more detail on the problem symptoms and some scoping.
Getting Started
As we saw in the first half, the customer’s management cluster was in a degraded state. This was due to one manager – 172.16.1.41 – being in a wonky half-broken state. Although we could ping it, we could not login and all of the services it was contributing to the NSX management cluster were down.
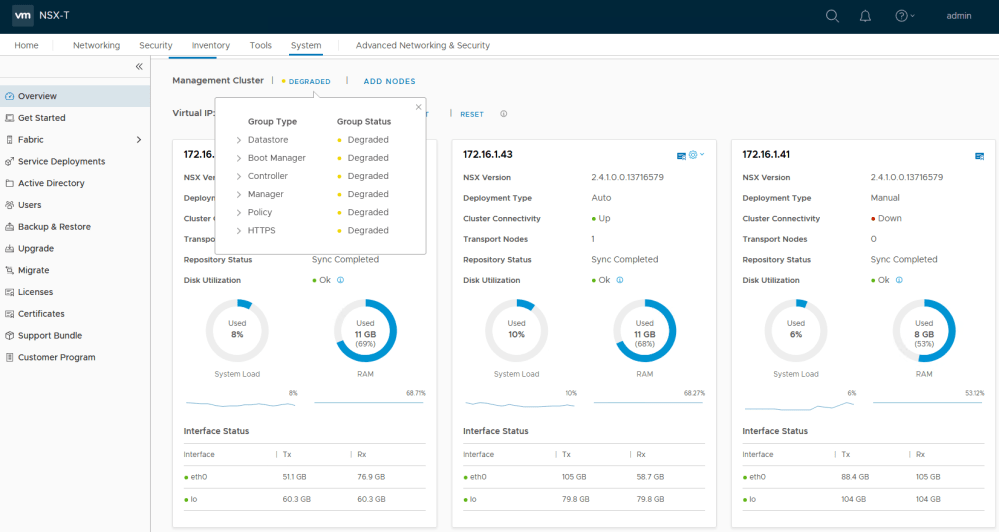
What was most telling, however, was the screenshot of the VM’s console window.
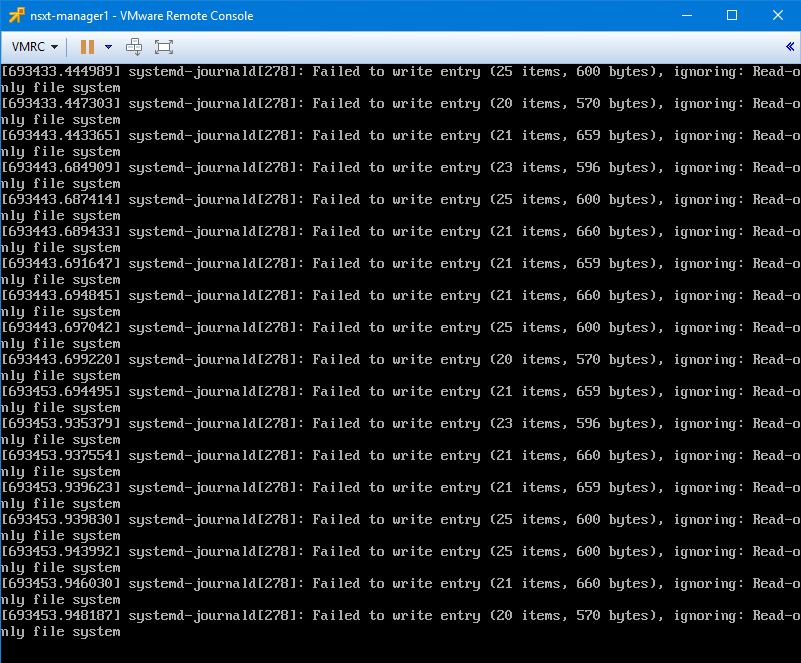
The most important keyword there was “Read-only file system”. As many readers had correctly guessed, this is a very common response to an underlying storage problem. Like most flavors of Linux, the Linux-based OS used in the NSX appliances will set their ext4 partitions to read-only in the event of a storage failure. This is a protective mechanism to prevent data corruption and further data loss.
When this happens, the guest may be partially functional, but anything that requires write access to the read-only partitions will obviously be in trouble. This is why we could ping the manager appliance, but all other functionality was broken. The manager cluster uses ZooKeeper for clustering services. ZooKeeper requires consistent and low-latency write access to disk. Because this wasn’t available to 172.16.1.41, it was marked as down in the cluster.
After discussing this with our fictional customer, we were able to confirm that an ESXi host esx-e3 experienced a total storage outage for a few minutes and that it had since been fixed. They had assumed it was not related because the appliance was on esx-e1, not esx-e3.
Continue reading “NSX-T Troubleshooting Scenario 3 – Solution”