It’s been a while since I’ve posted anything, so what better way to get back into the swing of things than a troubleshooting scenario! These last few months I’ve been busy learning the ropes in my new role as an SRE supporting NSX and VMware Cloud on AWS. Hopefully I’ll be able to start releasing regular content again soon.
Welcome to the third NSX-T troubleshooting scenario! What I hope to do in these posts is share some of the common issues I run across from day to day. Each scenario will be a two-part post. The first will be an outline of the symptoms and problem statement along with bits of information from the environment. The second will be the solution, including the troubleshooting and investigation I did to get there.
The Scenario
As always, we’ll start with a fictional customer problem statement:
“I’m not experiencing any problems, but I noticed that my NSX-T 2.4.1 manager cluster is in a degraded state. One of the unified appliances appears to be down. I can ping it just fine, but I can’t seem to login to the appliance via SSH. I’m sure I’m putting in the right password, but it won’t let me in. I’m not sure what’s going on. Please help!”
From the NSX-T Overview page, we can see that one appliance is red.
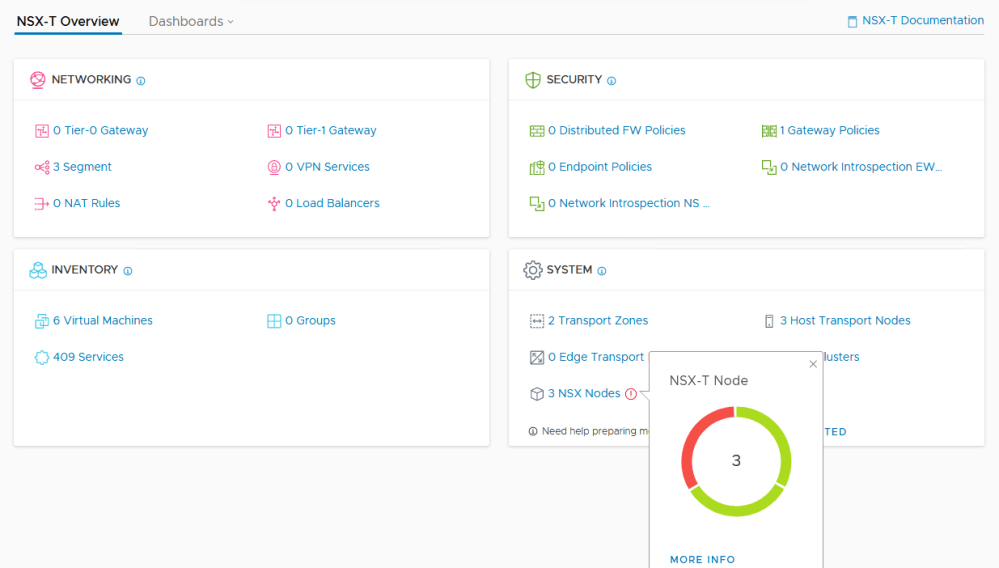
Let’s have a look at the management cluster in the UI:
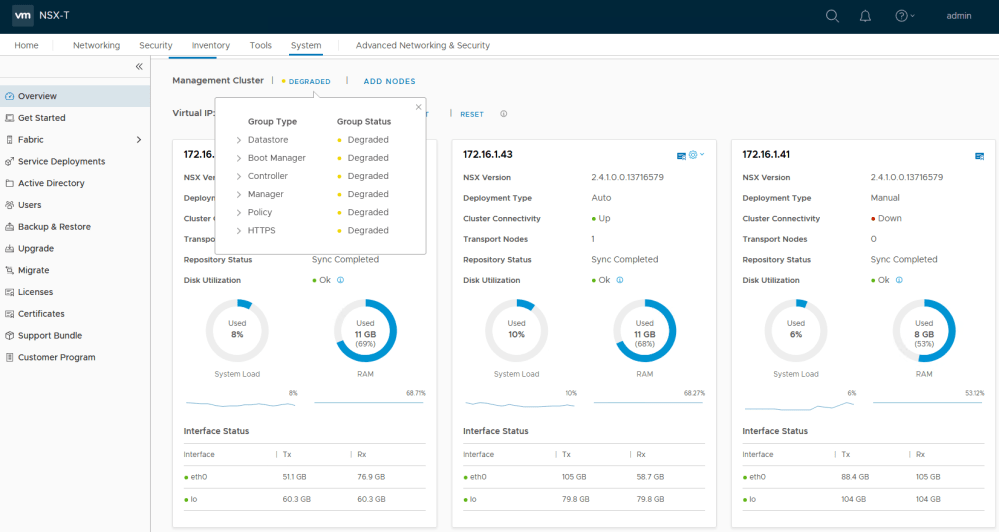
The problematic manager is 172.16.1.41. It’s reporting its cluster connectivity as ‘Down’ despite being reachable via ping. It appears that all of the services including controller related services are down for this appliance as well.
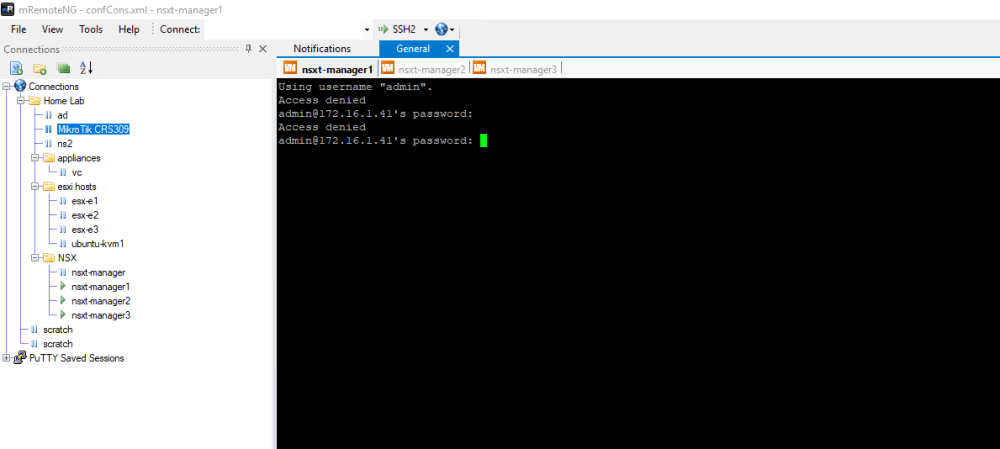
Strangely, it doesn’t appear to be accepting the admin or root passwords via SSH. We always get an ‘Access Denied’ response. We can login successfully to the other two appliances without issue using the same credentials.
Opening a console window to 172.16.1.41 greets us with the following:
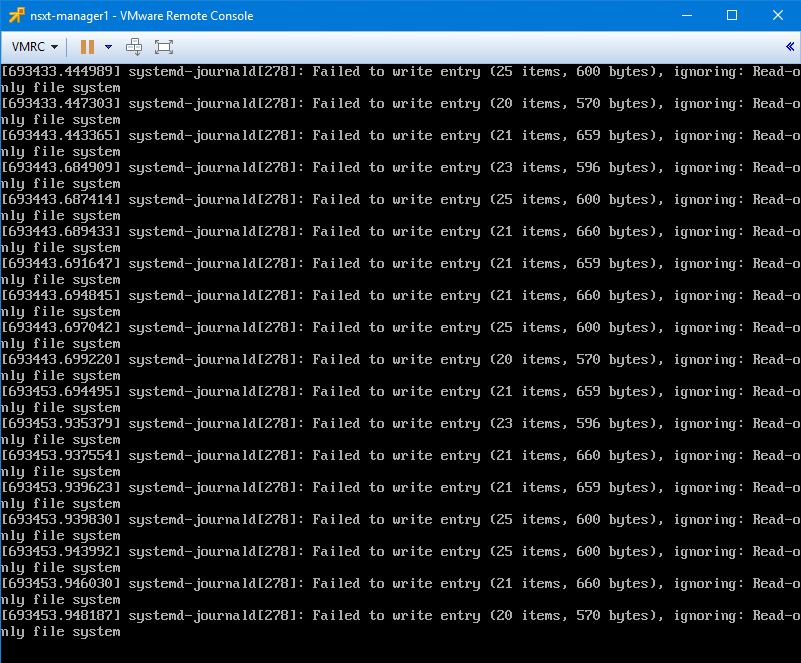
Error messages appear to continually scroll by from system-journald mentioning “Failed to write entry”. Hitting enter gives us the login prompt, but we immediately get the same error messages and can’t login.
What’s Next
It seems pretty clear that there is something wrong with 172.16.1.41, but what may have caused this problem? How would you fix this and most importantly, how can you root cause this?
I’ll post the solution in the next day or two, but how would you handle this scenario? Let me know! Please feel free to leave a comment below or via Twitter (@vswitchzero).

Very good post without the happy end so far.
How I would handle this scenario?
First of all, I would open SR with VMware GSS 🙂
In parallel, I would do my own troubleshooting.
I see the message ” … Read-only file system” … on the console. I would try to understand why the file system is in read-only mode. Problem with underlying storage?
Check storage on esx cluster. Fix where needed and reboot the server :> Read only file system can have multiple reasons. one of the is lost storage for a too long time. A reboot would help in that case.
– nfs storage maybe failed
– disk in datastore broken
It is clear the filesystem has gone into READ-ONLY mode, I would either fix the filesystem using e2fsk or I would redeploy the failed NSX- Manager in the cluster.