A better way to find your exact NIC model on the VMware Compatibility Guide.
If you’ve ever tried to search for a NIC in the VMware Compatibility Guide, you may have come up a much longer list of results than you expected. Many cards with similar names have subtle differences. Some have multiple hardware revisions, varying numbers or types of ports and may also be released by different OEMs. In some situations, the name of the card in the vSphere UI may not match what it truly is, adding to the confusion.
Thankfully, there is a much better way to identify your card. You can use the PCI VID, DID, SVID and SSID identifiers. The below video will walk through how to find these identifiers, as well as how to use them to find your specific card on the HCG.
Please feel free to leave any comments or questions below or on YouTube.
Taking the time to remove LUNs correctly is worth the effort and prevents all sorts of complications.
This is admittedly a well-covered topic in both the VMware public documentation and in blogs, but I thought I’d provide my perspective on this as well in case it may help others. Unfortunately, improper LUN removal is still something I encountered all too often when I worked in GSS years back.
Having done a short stint on the VMware storage support team, I knew all too well the chaos that would ensue after improper LUN decommissioning. ESX 4.x was particularly bad when it came to handling unexpected storage loss. Often hosts would become unmanageable and reboots were the only way to recover. Today, things are quite different. VMware has made many strides in these areas, including better host resiliency in the face of APD (all paths down) events, as well as introducing PDL (permenant device loss) several years back. Despite these improvements, you still don’t want to yank storage out from under your hypervisors.
Today, I’ll be decommissioning an SSD drive from my freenas server, which will require me to go through these steps.
Update: Below is a recent (2021) video I did on the process in vSphere 7.0:
Step 1 – Evacuate!
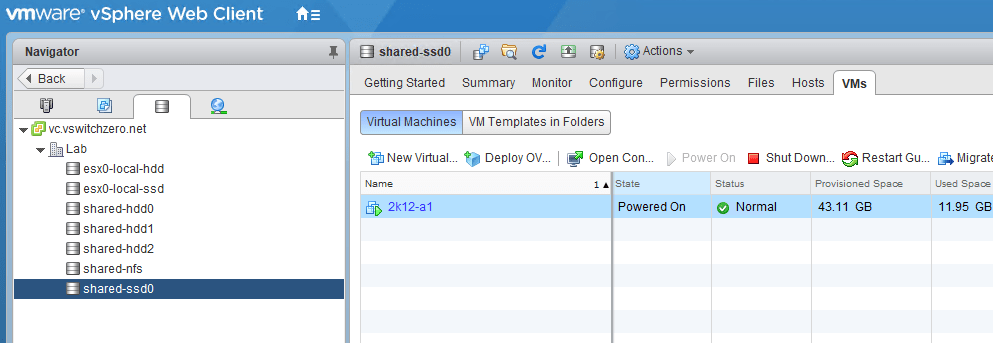
Before you even consider nuking a LUN from your SAN, you’ll want to ensure all VMs, templates and files have been migrated off. The easiest way to do this is to navigate to the ‘Storage’ view in the Web Client, and then select the datastore in question. From there, you can click the VMs tab. If you are running 5.5 or 6.0, you may need to go to ‘Related Objects’ first, and then Virtual Machines.
One VM still resides on shared-ssd0. It’ll need to be migrated off.
In my case, you can see that the datastore shared-ssd still has a VM on it that will need to be migrated. I was able to use Storage vMotion without interrupting the guest.
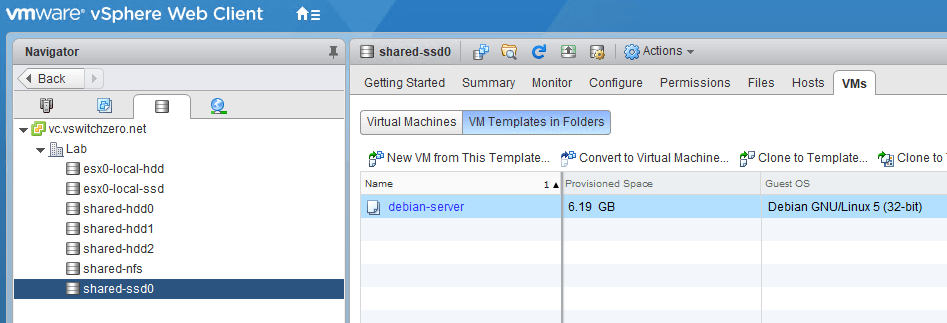
It’s easy to forget about templates as they aren’t visible in the default datastore view. Be sure to check for them as well.
Templates do not show up in the normal view, so be sure to check specifically for these as well. Remember, you can’t migrate templates. You’ll need to convert them to VMs first, then migrate them and convert them back to templates. I didn’t care about this one, so just deleted it from disk.
New bundled VMXNET3 driver corrects PSOD crash issue.
As mentioned in a recent post, a problem in the tools 10.3.0 bundled VMXNET3 driver could cause host PSODs and connectivity issues. As of September 12th, VMware Tools 10.3.2 is now available, which corrects this issue.
The problematic driver was version 1.8.3.0 in tools 10.3.0. According to the release notes, it has been replaced with version 1.8.3.1. In addition to this fix, there are four resolved issues listed as well.
VMware mentions the following in the 10.3.2 release notes:
I recently ran into some problems while deploying a Windows Server 2012 R2 VM in my vSphere 6.5 U2 lab. I’ve come to expect that the console mouse response is going to be terrible until VMware Tools is installed, but for some odd reason I had no mouse control whatsoever. Thinking it may be a quirk of the Web Console, I tried both the Remote Console and the HTML5 client to no avail.
The VM appeared to be healthy and would register keyboard input, but the motion of the mouse cursor was erratic or the cursor would not move at all. Thinking that I just needed to battle on and get Tools installed, I attempted to use the keyboard for this purpose – what a chore. You think it would have been easy, but the installer kept losing focus and falling behind other open windows. Many of the windows keyboard shortcuts I’d normally use were not functioning because they register on my laptop – not in the console. I couldn’t RDP to the VM either because the NIC needed to be configured with a valid IP address.
After doing a bit of research, it appeared that display scaling could cause all sorts of mouse issues – but this didn’t appear to be applicable in my case. That’s when I stumbled upon a communities thread that mentioned adding a USB controller to the VM. Even though my VM was ‘Hardware Version 13’, the USB 2.0 controller isn’t added by default.
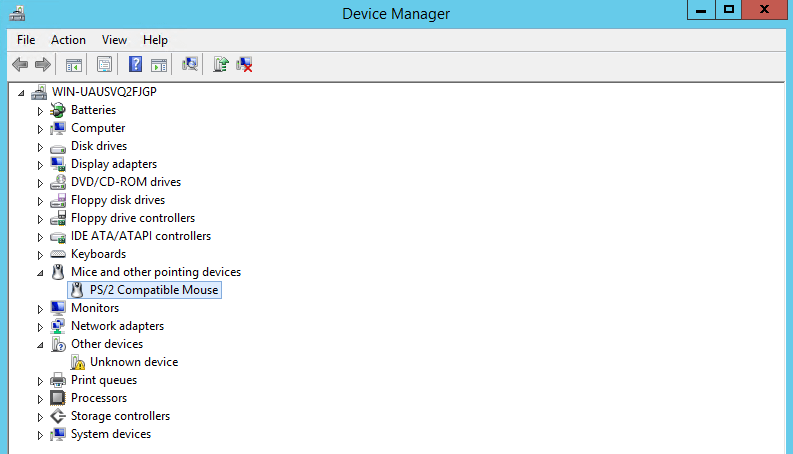
I managed to get to the device manager using the keyboard, and you can see that the virtual hardware will use a PS/2 a mouse in the absence of a USB controller:
I then went ahead and added the basic USB 2.0 controller to the VM and booted it up.
I have recently rebuilt my home lab – an all too common occurrence due to the number of times I intentionally try to break things. In the process of rebuilding, I had some ISO files I wanted to copy over to a datastore. The process failed and the Web Client greeted me with an uncharacteristically long error message.
The exact text reads:
“The operation failed for an undetermined reason. Typically, this problem occurs due to certificates that the browser does no trust. If you are using self-signed or custom certificates, open the URL below in a new browser tab and accept the certificate, then retry the operation.”
In my case, the URL that it listed was to one of my ESXi hosts in the compute-a cluster called esx-a2. The error then goes on to reference VMware KB 2147256.
It may seem odd that the vSphere Client would be telling you to visit a random ESXi host’s UI address when you are trying to upload a file via vCenter. But if you stop to think about it for a second, vCenter has no access whatsoever to your datastores. Whether you are trying to create a new VMFS datastore, upload a file or even just browse, vCenter must rely on an ESXi host with the necessary access to do the actual legwork. That ESXi host then relays the information back through the Web Client.
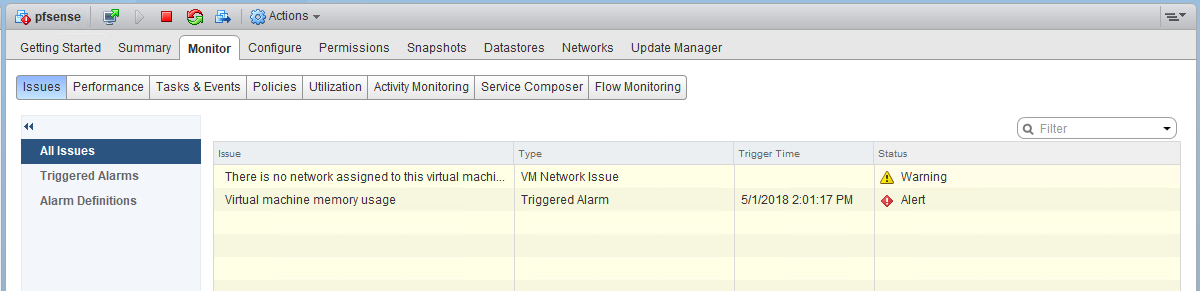
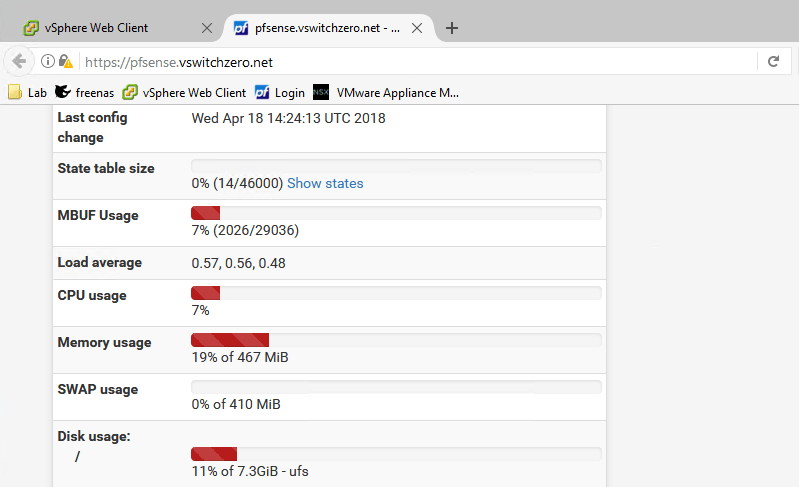
In the recent revamp of my lab environment, I decided to use VT-d passthrough for a pfsense VM. It has been working well with the integrated Intel igb based NICs on my management host, but I noticed that I started getting memory alarms on the VM.
At first, I thought I may have sized the VM a bit too small with only 512MB of RAM, but when checking in the guest itself, I saw only a small amount was actually being used:
At only 19% utilized, I’m nowhere near the 95% required to trigger this alarm. As you can see in the performance charts, all of the memory is being used by the guest from the perspective of ESXi:
But after thinking about this for a moment, it makes sense – one of the requirements for PCI passthrough is to reserve all guest memory. For passthrough to function, the hypervisor must provide 100% consistent and reliable memory to the guest. What better way to ensure that then to reserve and pin all memory to the VM.
Although I understand why all memory is active and consumed, it’s unfortunate that vCenter doesn’t take into consideration the reason for this. In my search for an answer, I came across VMware KB 2149787. It appears that this can impact not only VMs with passthrough, but also fault tolerant VMs and VMs with latency sensitivity set to ‘high’. Unfortunately, the resolution suggested is to disable to virtual machine memory alarm at the vCenter object level. This effectively disables the alarm for everything in the inventory. I hope that at some point, vSphere will allow disabling specific alarms on a per-VM basis because few people would want to take this approach.
For now, I think the best course of action is to simply click ‘Reset to Green’, which should clear the alarm until the VM is powered off/on again. Just keep in mind that this is normal for this type of VM and that the alarm can be disregarded.
I was recently speaking with someone about power management in a home lab environment. Their plan was to use USB passthrough to connect a UPS to a virtual machine in a vSphere cluster. From there, they could use PowerCLI scripting to gracefully power off the environment if the UPS battery got too low. This sounded like a wise plan.
Their concern was that the VM would need to be pinned to the host where the USB cable was connected and that vMotion would not be possible. To their pleasant surprise, I told them that support for vMotion of VMs with USB passthrough had been added at some point in the past and it was no longer a limitation.
When I started looking more into this feature, however, I discovered that this was not a new addition at all. In fact, this has been supported ever since USB passthrough was introduced in vSphere 4 over seven years ago. Have a look at the vSphere Administration Guide for vSphere 4 on page 105 for more information.
I had done some work with remote serial devices in the past, but I’ve never been in a situation where I needed to vMotion a VM with a USB device attached. It’s time to finally take this functionality for a test drive.
I’ve been playing around recently with VMware’s new Photon OS platform. Thanks to it’s incredibly small footprint and virtualization-specific tuning, it looks like an excellent building block for a custom appliance I’m hoping to build. To keep the appliance as small as possible, I used the minimal deployment and then planned to install packages as required.
After deploying the appliance, I hit a roadblock as the package management tool called tdnf couldn’t reach any of the repositories. This was expected as my home lab is isolated and I have to go through a squid proxy server to get to the outside world.
root@photon-machine [ ~ ]# tdnf repolist
curl#7: Couldn't connect to server
Error: Failed to synchronize cache for repo 'VMware Photon Linux 2.0(x86_64) Updates' from 'https://dl.bintray.com/vmware/photon_updates_2.0_x86_64'
Disabling Repo: 'VMware Photon Linux 2.0(x86_64) Updates'
curl#7: Couldn't connect to server
Error: Failed to synchronize cache for repo 'VMware Photon Linux 2.0(x86_64)' from 'https://dl.bintray.com/vmware/photon_release_2.0_x86_64'
Disabling Repo: 'VMware Photon Linux 2.0(x86_64)'
curl#7: Couldn't connect to server
Error: Failed to synchronize cache for repo 'VMware Photon Extras 2.0(x86_64)' from 'https://dl.bintray.com/vmware/photon_extras_2.0_x86_64'
Disabling Repo: 'VMware Photon Extras 2.0(x86_64)'
When trying to build the package cache, you can see that the the synchronization fails to specific HTTPS locations over port 443.
After having a quick look through the Photon administration guide, I was surprised to see that there wasn’t anything regarding proxy configuration listed – at least not at the time of writing. Doing some digging online turned up several possibilities. There seems to be numerous places in which a proxy can be defined – including in the kubernetes configuration, or specifically for the tdnf package manager.
The simplest way to get your proxy configured for tdnf, as well as other tools like WGET and Curl is to define a system-wide proxy. You’ll find the relevant configuration in the /etc/sysconfig/proxy file:
Using thin provisioned virtual disks can provide many benefits. Not only do they allow over-provisioning, but with the prevalence of flash storage, performance degradation really isn’t a concern like it used to be.
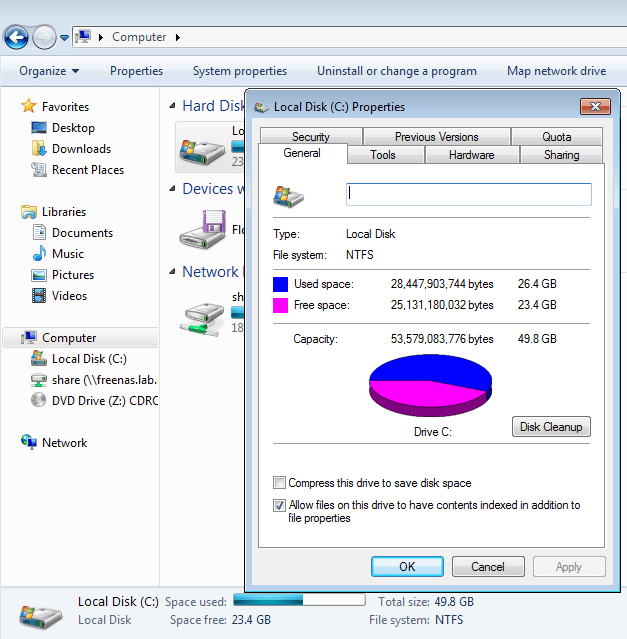
I recently ran into a situation in my home lab where my Windows jump box ran out of disk space. I had downloaded a bunch of OVA and ISO files and had forgotten to move them over to a shared drive that I use for archiving. I expanded the disk by 10GB to take it from 40GB to 50GB, and moved off all the large files. After this, I had about 26GB used and 23GB free – much better.
Because that jump box is sitting on flash storage – which is limited in my lab – I had thin provisioned this VM to conserve as much disk space as possible. Despite freeing up lots of space, the VM’s VMDK was still consuming a lot more than 26GB.
Notice below that doing a normal directory listing displays the maximum possible size of a thin disk. In this case, the disk has been expanded to 50GB:
[root@esx0:/vmfs/volumes/58f77a6f-30961726-ac7e-002655e1b06c/jump] ls -lha
total 49741856
drwxr-xr-x 1 root root 3.0K Feb 12 21:50 .
drwxr-xr-t 1 root root 4.1K Feb 16 16:13 ..
-rw-r--r-- 1 root root 41 Jun 16 2017 jump-7a99c824.hlog
-rw------- 1 root root 13 May 29 2017 jump-aux.xml
-rw------- 1 root root 4.0G Nov 25 18:47 jump-c49da2be.vswp
-rw------- 1 root root 3.1M Feb 12 21:50 jump-ctk.vmdk
-rw------- 1 root root 50.0G Feb 16 17:55 jump-flat.vmdk
-rw------- 1 root root 8.5K Feb 16 15:26 jump.nvram
-rw------- 1 root root 626 Feb 12 21:50 jump.vmdk
Using the ‘du’ command – for disk usage – we can see the flat file containing the data is still consuming over 43GB of space:
[root@esx0:/vmfs/volumes/58f77a6f-30961726-ac7e-002655e1b06c/jump] du -h *flat*.vmdk
43.6G jump-flat.vmdk
After procrastinating for a while, I finally started the upgrade process in my home lab to go from vSphere 6.0 to 6.5. The PSC upgrade was smooth, but I hit a roadblock when I started the upgrade process on the vCenter Server appliance.
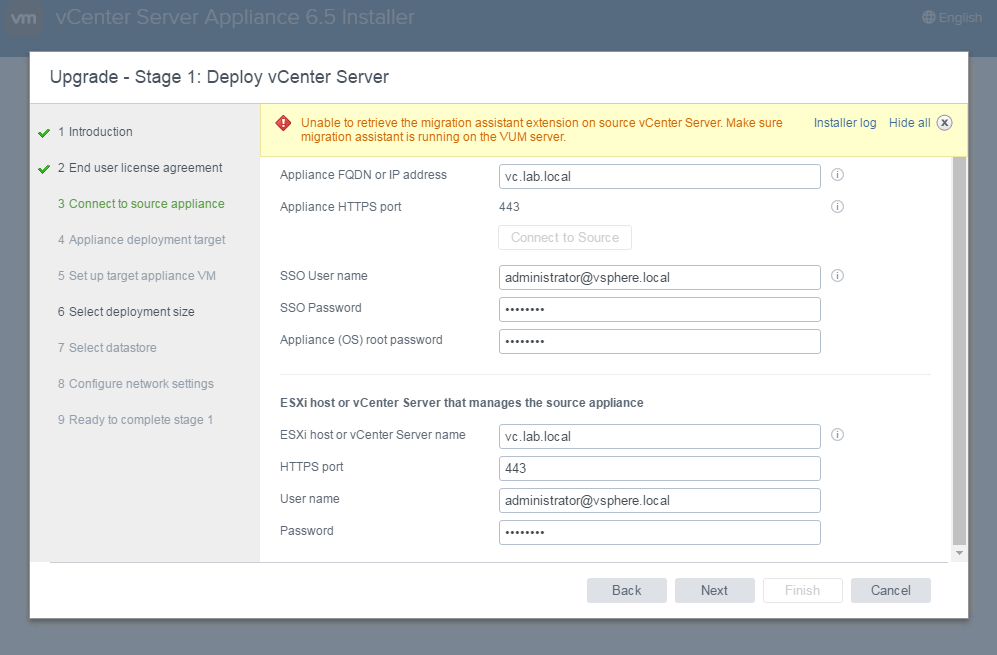
After going through some of the first steps in the process, I ran into the following error when trying to connect to the source appliance.
The exact text of the error reads:
“Unable to retrieve the migration assistant extension on source vCenter Server. Make sure migration assistant is running on the VUM server.”
I had forgotten that I even had Update Manager deployed. Because my lab is small, I generally applied updates manually to my hosts via the CLI. What I do remember, however, is being frustrated that I had to deploy a full-scale Windows VM to run the Update Manager service.