Welcome to the third installment of my new NSX troubleshooting series. What I hope to do in these posts is share some of the common issues I run across from day to day. Each scenario will be a two-part post. The first will be an outline of the symptoms and problem statement along with bits of information from the environment. The second will be the solution, including the troubleshooting and investigation I did to get there.
NSX Troubleshooting Scenario 3
I’ll start off again with a brief customer problem description:
“We’ve recently deployed Cross-vCenter NSX for a remote datacenter location. All of the VMs at that location don’t have connectivity. They can’t ping their gateway, nor can they ping VMs on other hosts. Only VMs on the same host can ping each other.”
This is a pretty vague description of the problem, so let’s have a closer look at this environment. To begin, let’s look at the high-level physical interconnection between datacenters in the following diagram:
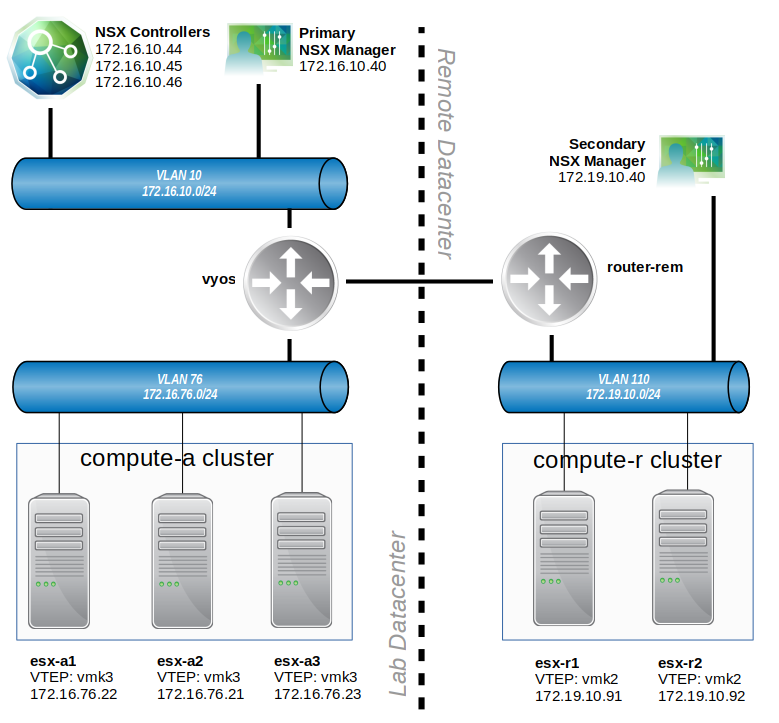
There isn’t a lot of detail above, but it helps to give us some talking points. The main location is depicted on the left. A three host cluster called compute-a exists there. All of the VLAN backed networks route through a router called vyos. The Universal Control Cluster exists at this location, as does the primary NSX manager.