Welcome to the seventh installment of a new series of NSX troubleshooting scenarios. Thanks to everyone who took the time to comment on the first half of scenario seven. Today I’ll be performing some troubleshooting and will show how I came to the solution.
Please see the first half for more detail on the problem symptoms and some scoping.
Getting Started
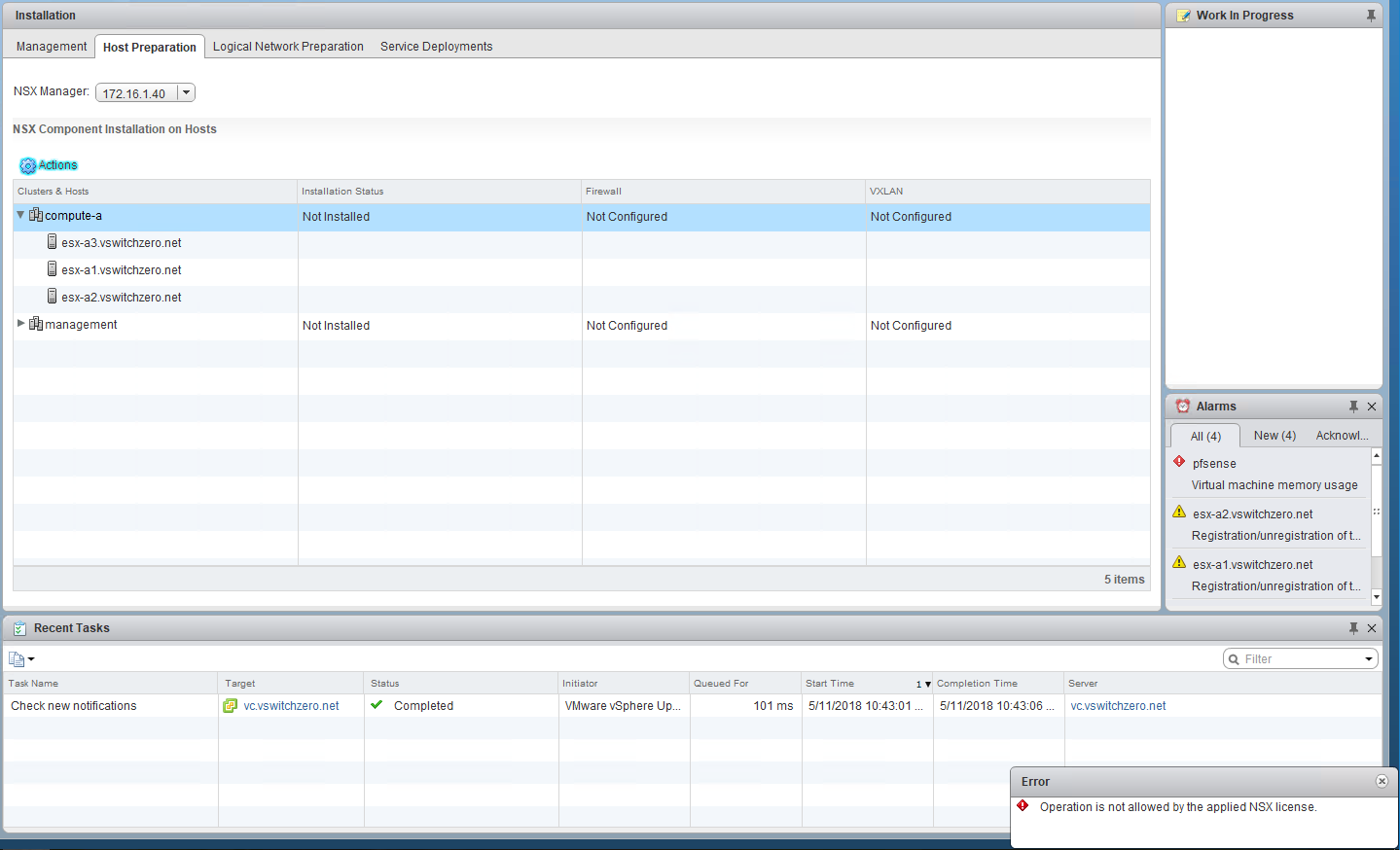
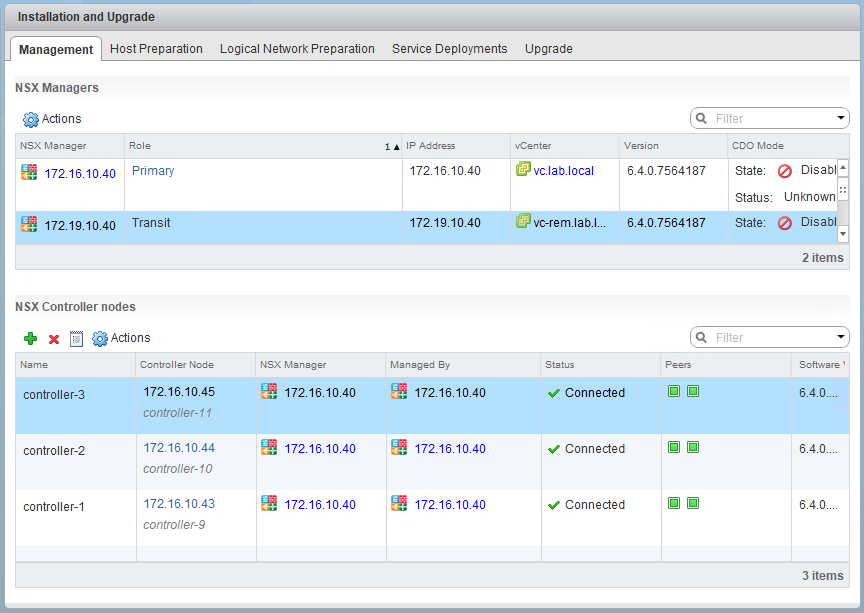
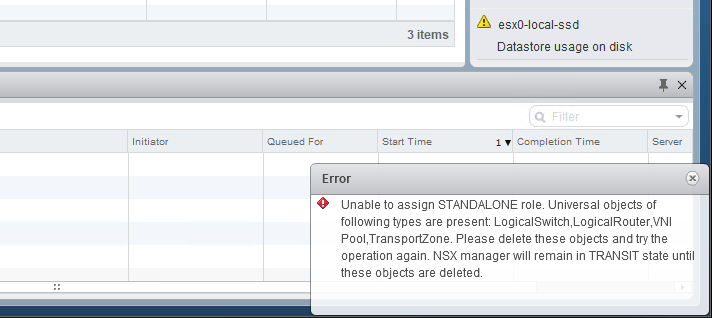
In the first half of this scenario, we saw that our fictional customer was hitting an exception every time they tried to convert their secondary – now a transit – NSX Manager to the standalone role. The error message seemed to imply that numerous universal objects were still in the environment.
Our quick spot checks didn’t show any lingering universal objects, but looking at the NSX Manager logging can tell us a bit more about what still exists:
2018-03-26 22:27:21.779 GMT INFO http-nio-127.0.0.1-7441-exec-1 ReplicationConfigurationServiceImpl:152 - - [nsxv@6876 comp="nsx-manager" subcomp="manager"] Role validation successful
2018-03-26 22:27:21.792 GMT INFO http-nio-127.0.0.1-7441-exec-1 DefaultUniversalSyncListener:61 - - [nsxv@6876 comp="nsx-manager" subcomp="manager"] 1 universal objects exists for type VdnScope
2018-03-26 22:27:21.793 GMT INFO http-nio-127.0.0.1-7441-exec-1 DefaultUniversalSyncListener:66 - - [nsxv@6876 comp="nsx-manager" subcomp="manager"] Some objects are (printing maximum 5 names): Universal TZ
2018-03-26 22:27:21.794 GMT INFO http-nio-127.0.0.1-7441-exec-1 DefaultUniversalSyncListener:61 - - [nsxv@6876 comp="nsx-manager" subcomp="manager"] 1 universal objects exists for type Edge
2018-03-26 22:27:21.797 GMT INFO http-nio-127.0.0.1-7441-exec-1 DefaultUniversalSyncListener:66 - - [nsxv@6876 comp="nsx-manager" subcomp="manager"] Some objects are (printing maximum 5 names): dlr-universal
2018-03-26 22:27:21.798 GMT INFO http-nio-127.0.0.1-7441-exec-1 DefaultUniversalSyncListener:61 - - [nsxv@6876 comp="nsx-manager" subcomp="manager"] 5 universal objects exists for type VirtualWire
2018-03-26 22:27:21.806 GMT INFO http-nio-127.0.0.1-7441-exec-1 DefaultUniversalSyncListener:66 - - [nsxv@6876 comp="nsx-manager" subcomp="manager"] Some objects are (printing maximum 5 names): Universal Transit, Universal Test, Universal App, Universal Web, Universal DB
2018-03-26 22:27:21.809 GMT INFO http-nio-127.0.0.1-7441-exec-1 L2UniversalSyncListenerImpl:58 - - [nsxv@6876 comp="nsx-manager" subcomp="manager"] Global VNI pool exists
2018-03-26 22:27:21.814 GMT WARN http-nio-127.0.0.1-7441-exec-1 ReplicationConfigurationServiceImpl:101 - - [nsxv@6876 comp="nsx-manager" subcomp="manager"] Setting role to TRANSIT because following object types have universal objects VniPool,VdnScope,Edge,VirtualWire
2018-03-26 22:27:21.816 GMT INFO http-nio-127.0.0.1-7441-exec-1 AuditingServiceImpl:174 - - [nsxv@6876 comp="nsx-manager" subcomp="manager"] [AuditLog] UserName:'LAB\mike', ModuleName:'UniversalSync', Operation:'ASSIGN_STANDALONE_ROLE', Resource:'', Time:'Mon Mar 26 14:27:21.815 GMT 2018', Status:'FAILURE', Universal Object:'false'
2018-03-26 22:27:21.817 GMT WARN http-nio-127.0.0.1-7441-exec-1 RemoteInvocationTraceInterceptor:88 - Processing of VsmHttpInvokerServiceExporter remote call resulted in fatal exception: com.vmware.vshield.vsm.replicator.configuration.facade.ReplicatorConfigurationFacade.setAsStandalonere.vshield.vsm.exceptions.InvalidArgumentException: core-services:125023:Unable to assign STANDALONE role. Universal objects of following types are present:
If you look closely at the messages above, you can see a list of what still exists. Keep in mind that a maximum of five objects per category is included in the log messages. In this case, they are:
Transport Zones: Universal TZ
Edges: dlr-universal
Logical Switches: Universal Transit, Universal Test, Universal App, Universal Web, Universal DB
VNI Pools: 1 exists
This is indeed a list of everything the customer claims to have deleted from the environment. From the perspective of the ‘Transit’ manager, these objects still exist for some reason.
How We Got Here
Looking back at the order of operations the user did tells us something important:
- First, he disconnected the secondary NSX Manager from the primary. This was successful, and it changed its role from Secondary to ‘Transit’.
- Next, he attempted to convert it to a ‘Standalone’ manager. This failed with the same error message mentioned earlier. This seemed valid, however, because those objects really did exist.
- At this point, he removed the remaining universal logical switches, edges and transport zone. These were all deleted successfully.
- The subsequent attempts to convert the manager to a ‘Standalone’ continue to fail with the same error message even though the objects are gone.
Notice the very first step – they disconnected the secondary from the primary NSX Manager.
Continue reading “NSX Troubleshooting Scenario 7 – Solution”