Welcome to the fourth installment of a new series of NSX troubleshooting scenarios. Thanks to everyone who took the time to comment on the first half of scenario four. Today I’ll be performing some troubleshooting and will resolve the issue.
Please see the first half for more detail on the problem symptoms and some scoping.
Getting Started
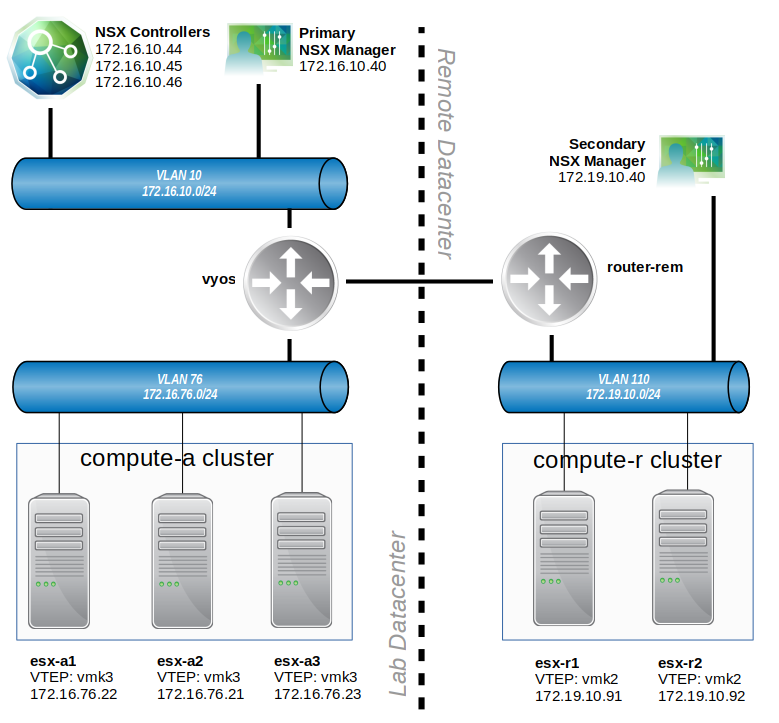
During the scoping in the first half of the scenario, we saw that the problem was squarely in the customer’s new secondary NSX deployment. Two test virtual machines – linux-r1 and linux-r2 – could not be added to any of the universal logical switches.
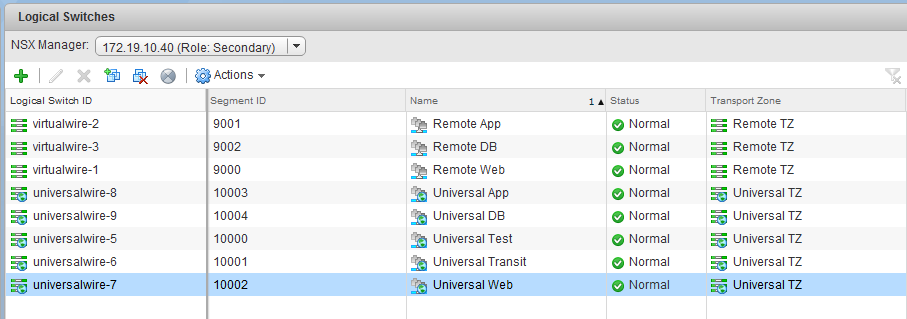
From the ‘Logical Switches’ view in the NSX Web Client UI, we could see that these universal logical switches were synchronized across both NSX Managers. These existed from the perspective of the Primary and Secondary manager views:
Perhaps the most telling observation, however, was the absence of distributed port groups associated with the universal logical switches on the dvs-rem switch:
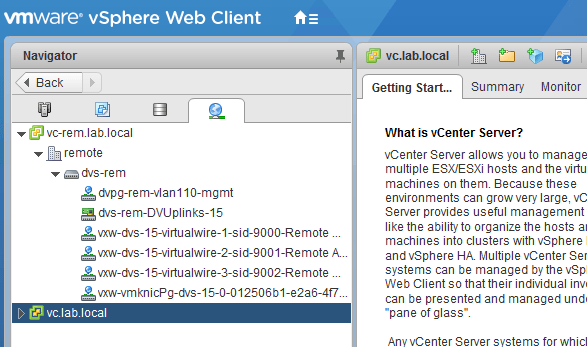
As we can see above, the port groups do exist for logical switches in the VNI 900x range. These are non-universal, logical switches available to the secondary NSX deployment only.
In the host preparation section, we can see that dvs-rem is indeed the configured distributed switch for the compute-r cluster and that both hosts look good from a VTEP/VXLAN perspective:
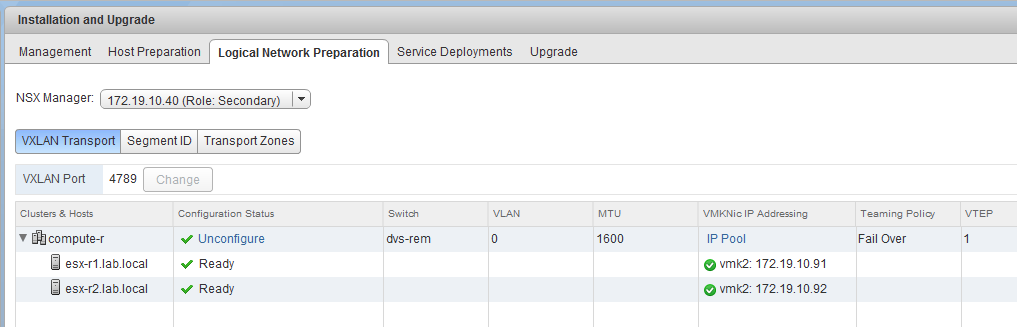
So why are these port groups missing? Without them, VMs simply can’t be added to the associated logical switches.
The Solution
Although you’ve probably noticed that I like to dig deep in some of these scenarios, this one is actually pretty straight forward. A straight forward, but all too common problem – the cluster has not been added to the universal transport zone.
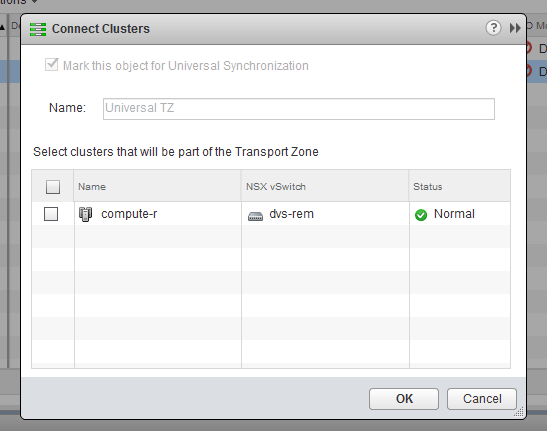
You’d be surprised how often I see this, but to be fair, it’s very easily overlooked. I sometimes need to remind myself to check all the basics first, especially when dealing with new deployments. The key symptom that raised red flags for me was the lack of auto-generated port groups on the distributed switch. The addition of the cluster to the transport zone will trigger the creation of these port groups. If they don’t exist, this should be the first thing that is checked.
As soon as I added the compute-r cluster to the Universal TZ transport zone, we see an immediate slew of portgroup creation tasks:
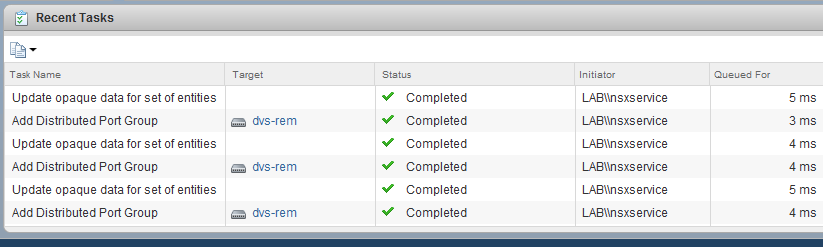
I’ve now essentially told NSX that I want all the logical switches in that transport zone to span to the compute-r cluster. In NSX-V, we can think of a transport zone as a boundary spanning one or more clusters. Only clusters in that transport zone will have the logical switches available to them for use.
The concept of a ‘Universal Transport Zone’ just takes this a step further and allows clusters in different vCenter instances to connect to the same universal logical switches. The fact that we saw portgroups for the 9000-900X range of VNIs tells us that the compute-r cluster existed in the non-universal Transport Zone called ‘Remote TZ’, but was missing from ‘Universal TZ’.
Conclusion
Thanks again to everyone for posting their testing suggestions and theories! I hope you enjoyed this scenario. If you have other suggestions for troubleshooting scenarios you’d like to see, please leave a comment, or reach out to me on Twitter (@vswitchzero).