FreeNAS is a very powerful storage solution and is quite popular with those running vSphere and NSX home labs. I recently built a new FreeNAS 9.10 system and wanted to share some of my experiences getting NSX FTP backups going.
To get this configured, I found the FTP section of the FreeNAS 9.10 documentation to be very useful. I’d definitely recommend giving it a read through as well.
Before Getting Started
Before enabling the FTP service in FreeNAS, you’ll want to decide where to put your NSX backups. In theory, you can dump them in any of your volumes or datasets but you may want to set aside a specific amount of storage space for them. To do this in my lab, I created a dedicated dataset with a 60GB quota for FTP purposes. I like to separate it out to ensure nothing else competes with the backups and the amount of space available is predictable.
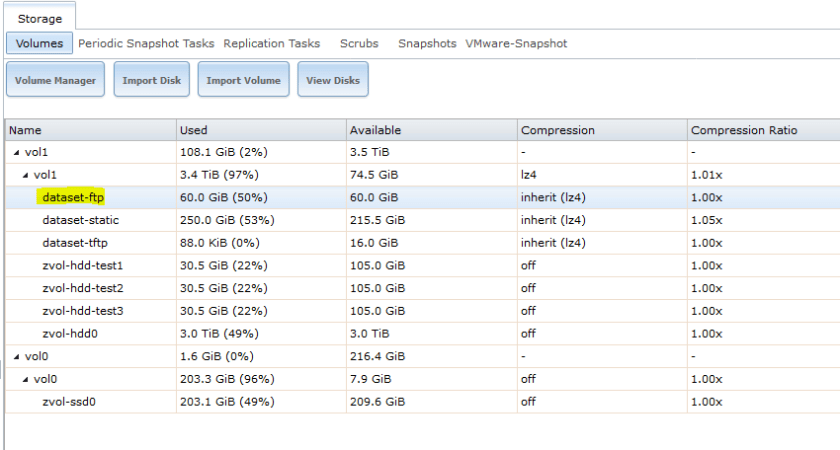
If you plan to use FTP for more than just NSX, it would be a good idea to create a subdirectory in the dataset or other location you want them to reside. In my case, I created a directory called ‘NSX’ in the dataset:
[root@freenas] ~# cd /mnt/vol1/dataset-ftp
[root@freenas] /mnt/vol1/dataset-ftp# mkdir NSX
[root@freenas] /mnt/vol1/dataset-ftp# ls -lha
total 2
drwxr-xr-x 3 root wheel 3B Sep 7 09:23 ./
drwxr-xr-x 5 root wheel 5B Sep 5 16:13 ../
drwxr-xr-x 2 root wheel 2B Sep 7 09:23 NSX/
[root@freenas] /mnt/vol1/dataset-ftp#
Setting Permissions
One step that is often missed during FreeNAS FTP configuration is to set the appropriate permissions. The proftpd service in FreeNAS uses the built in ftp user account. If that user does not have the appropriate permissions to the location you intend to use, backups will not write successfully.
Since I used a dedicated dataset for FTP called dataset-ftp, I can easily set permissions recursively for this location from the UI:
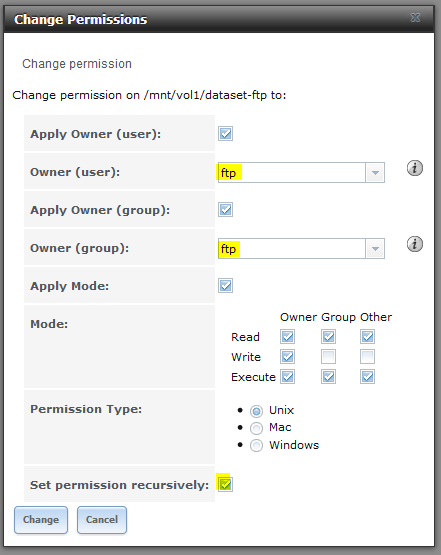
As shown above, we want to set both the owner user and group to ftp. Because I created the NSX directory within the dataset, I’ll be setting permission recursively as well.
If I log into FreeNAS via SSH or console again, I can confirm that this worked because the dataset-ftp mount is now owned by ftp as is the NSX subdirectory within.
[root@freenas] /mnt/vol1# ls -lha
total 14
drwxrwxr-x 5 root wheel 5B Sep 5 16:13 ./
drwxr-xr-x 4 root wheel 192B Sep 5 16:09 ../
drwxr-xr-x 3 ftp ftp 3B Sep 7 09:23 dataset-ftp/
drwxrwxr-x 5 root wheel 13B Jul 29 16:23 dataset-static/
drwxrwxr-x 2 root wheel 2B Sep 5 16:13 dataset-tftp/
[root@freenas] /mnt/vol1# ls -lha dataset-ftp
total 2
drwxr-xr-x 3 ftp ftp 3B Sep 7 09:23 ./
drwxrwxr-x 5 root wheel 5B Sep 5 16:13 ../
drwxr-xr-x 2 ftp ftp 2B Sep 7 13:46 NSX/
The Easy Option – Anonymous FTP Access
Setting up anonymous FTP access requires the least amount of effort and is usually sufficient for home lab purposes. I would strongly discourage the use of anonymous access in a production or security sensitive environment as anyone on the network can access the FTP directory configured.
First, configure FTP under services in the FreeNAS UI:
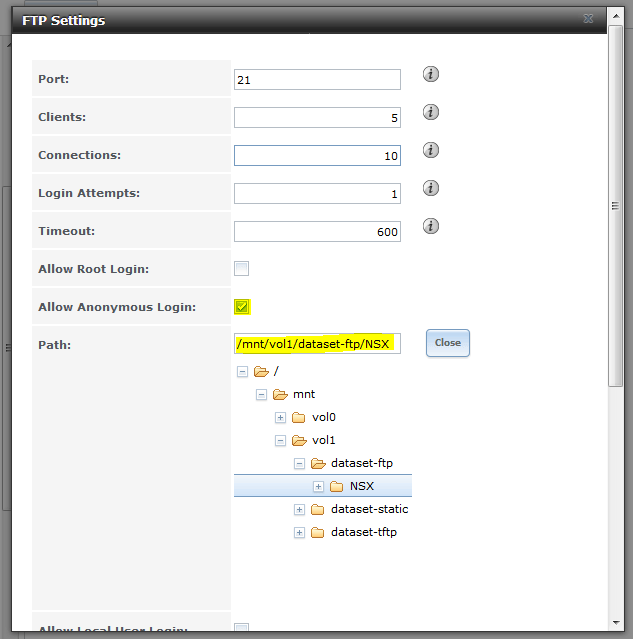
As you’d obviously expect, the ‘Allow Anonymous Login’ option needs to be checked off in order for anonymous FTP to work. The ‘Allow Local Users Login’ option should be unchecked if you don’t want to use authentication. It’s also important to select the ‘Path’ to the FTP root directory you wish to use. In my example above, any anonymous FTP logins will go directly into the NSX subdirectory I created earlier.
If you want to use FTP for more than just NSX backups, you can make the path the root of the dataset and NSX can be configured to use a specific subdirectory within as I’ll show later.
Once that’s done, you can enable the FTP service. It’ll be off by default:
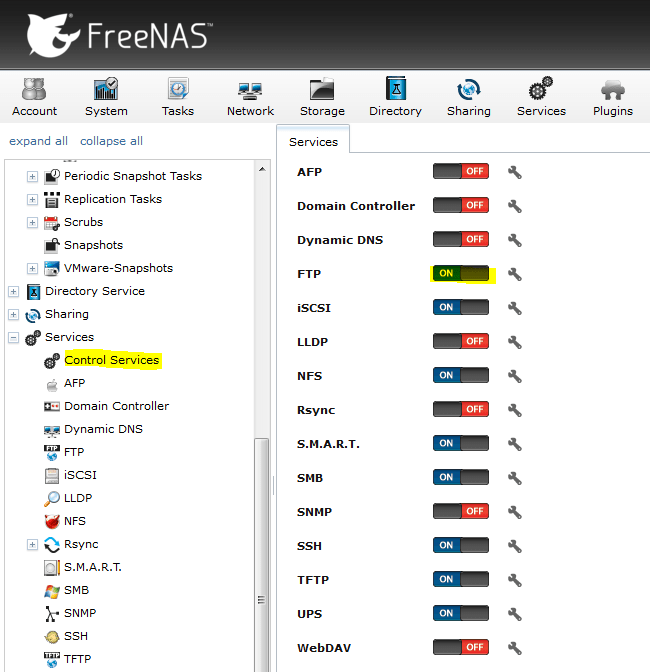
Now we can do some basic tests to ensure FTP is functional. You can use an FTP client like FileZilla if you like, but I’m just going to use the good old Windows FTP command line utility. First, let’s make sure we can login anonymously:
C:\Users\mike.LAB\Desktop>ftp freenas.lab.local
Connected to freenas.lab.local.
220 ProFTPD 1.3.5a Server (freenas.lab.local FTP Server) [::ffff:172.16.10.17]
User (freenas.lab.local:(none)): anonymous
331 Anonymous login ok, send your complete email address as your password
Password:
230 Anonymous access granted, restrictions apply
A return status of 230 is what we’re looking for here and this seems to work fine. Keep in mind that it technically doesn’t matter what password you enter for the anonymous username. You can just hit enter, but I usually just re-enter the username. It’s not necessary to enter anything that resembles an email address.
Next, let’s make sure we have permission to write to this location. I’ll do an FTP ‘PUT’ of a small text file:
ftp> bin
200 Type set to I
ftp> put C:\Users\mike.LAB\Desktop\test.txt
200 PORT command successful
150 Opening BINARY mode data connection for test.txt
226 Transfer complete
ftp: 14 bytes sent in 0.00Seconds 14000.00Kbytes/sec.
ftp> dir
200 PORT command successful
150 Opening ASCII mode data connection for file list
-rw-r----- 1 ftp ftp 14 Sep 7 13:56 test.txt
226 Transfer complete
ftp: 65 bytes received in 0.01Seconds 10.83Kbytes/sec.
ftp>
As seen above, the file was written successfully with a 226 return code. The last step I’d recommend doing before configuring NSX is to confirm the relative path after login from the FTP server’s perspective. Because I stayed in the FTP root directory, it simply lists a forward slash as shown below:
ftp> pwd
257 "/" is the current directory
ftp>
NSX expects this path as you’ll see shortly. Now that we know anonymous FTP is working, we can configure the FTP server from the NSX appliance UI:
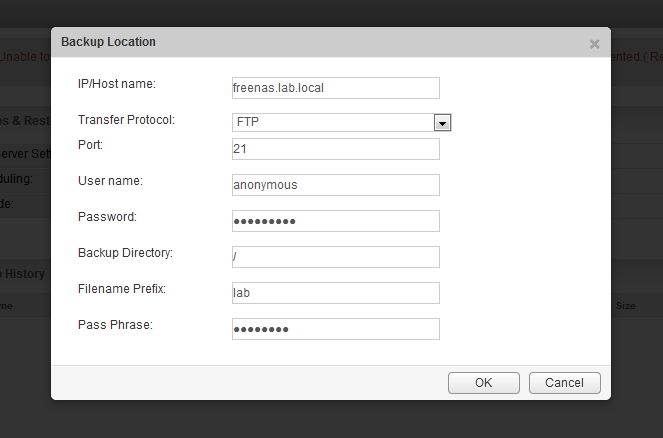
As you can see above, I’ve entered ‘anonymous’ as the user name, and entered the same as the password string. The backup directory is the location you want NSX to write backups to. If you had a specific directory you wanted to use within the FTP root directory that was configured, you could enter it here. For example, /backups. As mentioned earlier, my FTP root directory is the NSX directory so it’s not necessary in my case.
Two other pieces of information are mandatory in NSX – the filename prefix and the pass phrase. The filename prefix is just that – a string that is appended to the beginning of the filename. It usually makes sense to identify the environment or NSX manager by name here. This is especially important if you have multiple NSX managers all backing up to one location. The pass phrase is a password used to encrypt the backup binary file generated. Be sure not to lose this or you will not be able to restore your backups.
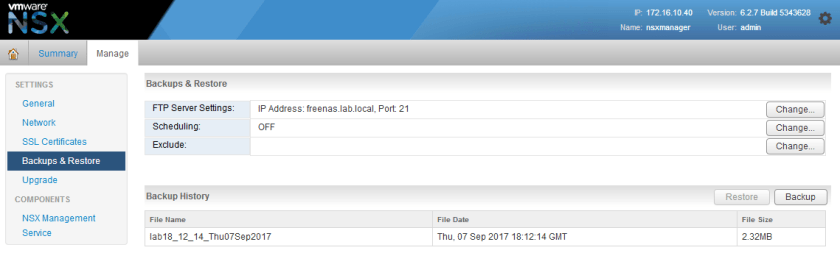
After hitting OK, we can then do a quick backup to ensure it can connect and write to the location configured.
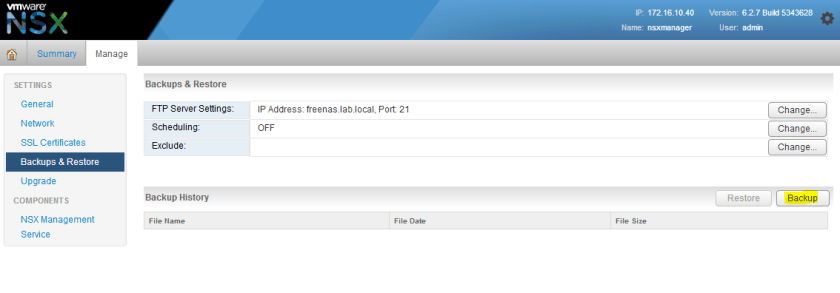
If everything was successful, you should then see your file listed in the backup history pane at the bottom of the view:
FTP User Authentication
Anonymous FTP may be sufficient for most home lab purposes, but there are several advantages to configuring users and authentication. FTP by nature transmits in plain text and is not secure, but adding authentication provides a bit more control over who can access the backups and allows the direction of users to specific FTP locations. This can be useful if you plan to use your FTP server for more than just NSX.
Before we begin, let’s create a user in FreeNAS that we’ll use for NSX backups:
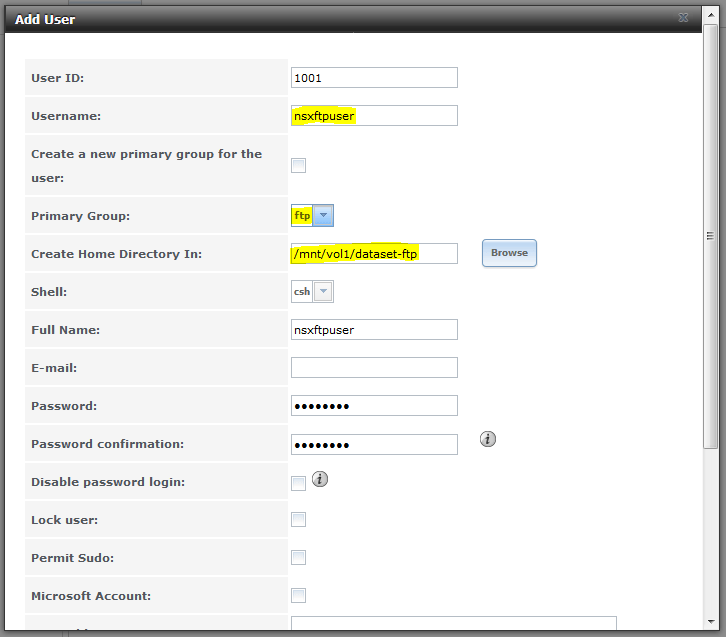
Some of the key things you’ll need to ensure is that the user’s primary group is the built-in ftp group used by proftpd and that the user’s home directory is where you want them to land after log in. In my example above, I’m creating a user called nsxftpuser with a home directory of the FTP root directory I configured earlier.
Keep in mind that by default FreeNAS will create a new home directory hence the wording “Create Home Directory In:”. I expect the home directory to actually be /mnt/vol1/dataset-ftp/nsxftpuser and not /mnt/vol1/dataset-ftp/.
Next, we need to modify the FTP settings slightly:
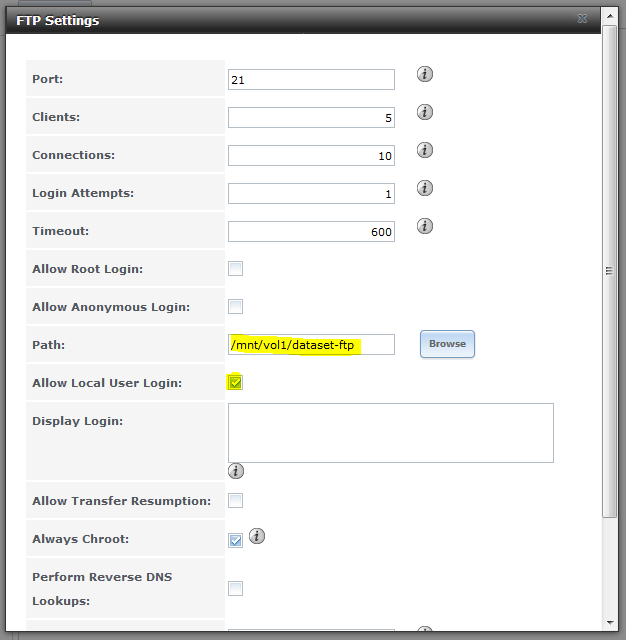
Since we want to use local user authentication, we need to check ‘Allow Local User Login’. I’ve also unchecked ‘Allow Anonymous Login’ to ensure only authenticated users can now login.
In order to test that we’re dumped into the user’s home directory after login, I changed the FTP default path one level back to the root of the dataset.
As a last step, it’s necessary to stop and start the FTP service again for the changes to take effect.
Before we test this new user, let’s double check that the home directory is located where we want it:
[root@freenas] /mnt/vol1/dataset-ftp# ls -lha
total 18
drwxr-xr-x 4 ftp ftp 4B Sep 7 14:42 ./
drwxrwxr-x 5 root wheel 5B Sep 5 16:13 ../
drwxr-xr-x 2 ftp ftp 5B Sep 7 14:43 NSX/
drwxr-xr-x 2 nsxftpuser ftp 10B Sep 7 14:42 nsxftpuser/
As you can see above, we now have a home directory matching the username in the FTP root location.
Now let’s try to log in using the nsxftpuser account:
C:\Users\mike.LAB\Desktop>ftp freenas.lab.local
Connected to freenas.lab.local.
220 ProFTPD 1.3.5a Server (freenas.lab.local FTP Server) [::ffff:172.16.10.17]
User (freenas.lab.local:(none)): nsxftpuser
331 Password required for nsxftpuser
Password:
230-Welcome to FreeNAS FTP Server
230 User nsxftpuser logged in
ftp>
So far so good, now let’s PUT a file to ensure we have write access to this location:
ftp> bin
200 Type set to I
ftp> put C:\Users\mike.LAB\Desktop\test.txt
200 PORT command successful
150 Opening BINARY mode data connection for test.txt
226 Transfer complete
ftp: 14 bytes sent in 0.00Seconds 14000.00Kbytes/sec.
ftp> dir
200 PORT command successful
150 Opening ASCII mode data connection for file list
-rw-r----- 1 nsxftpuser ftp 14 Sep 7 14:45 test.txt
226 Transfer complete
ftp: 67 bytes received in 0.00Seconds 22.33Kbytes/sec.
Success! The last thing we need to do is modify the NSX configuration slightly to use the new user account:
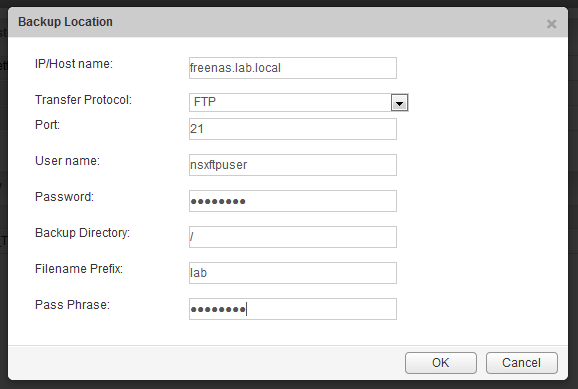
And sure enough, the backup was successful at 18:47 GMT:
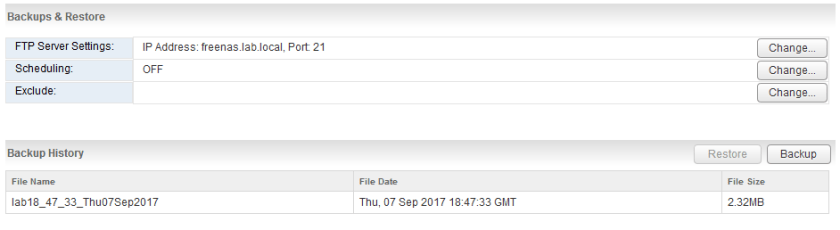
If I look at the files from the FreeNAS SSH session, I can see both the encrypted backup binary and metadata properties file located in the user’s home directory:
[root@freenas] /mnt/vol1/dataset-ftp/nsxftpuser# ls -lha lab*
-rw-r----- 1 nsxftpuser ftp 2.4M Sep 7 14:47 lab18_47_33_Thu07Sep2017
-rw-r----- 1 nsxftpuser ftp 227B Sep 7 14:47 lab18_47_33_Thu07Sep2017.backupproperties
Scheduling Backups
Once we know NSX backups are functional, it’s a good idea to get them going on a schedule.
An important consideration to keep in mind when deciding when to schedule is when your vCenter backups are done. Because NSX relies heavily upon the state of the vCenter Server inventory and objects, it’s a good idea to try to schedule your backups at around the same time. That way, if you ever need to restore, you’ll have vCenter and NSX objects in sync as closely as possible.
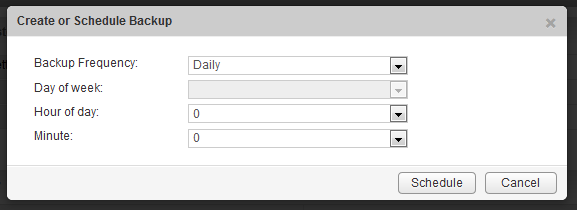
In my lab, I have it backing up every night at midnight, but depending on how dynamic your environment is, you may want to do it more frequently.
Another important point to note is that NSX Manager doesn’t handle large numbers of backups very well in the backup directory. The UI will throw a warning once you get up to 100 backups and eventually you’ll get a slow or non-responsive UI in the Backup and Restore section. To get around this, you can manually archive older backups to another location outside of the FTP root directory or create a script to move older files to another location.
The only piece that I haven’t gotten to work with FreeNAS yet is SFTP encrypted backups using TLS. Once I get that going well, I’ll hopefully write up another post on the topic.
Thanks for reading! If you have any questions please leave a comment below.