Welcome to the twelfth installment of a new series of NSX troubleshooting scenarios. Thanks to everyone who took the time to comment on the first half of the scenario. Today I’ll be performing some troubleshooting and will show how I came to the solution.
Please see the first half for more detail on the problem symptoms and some scoping.
Getting Started
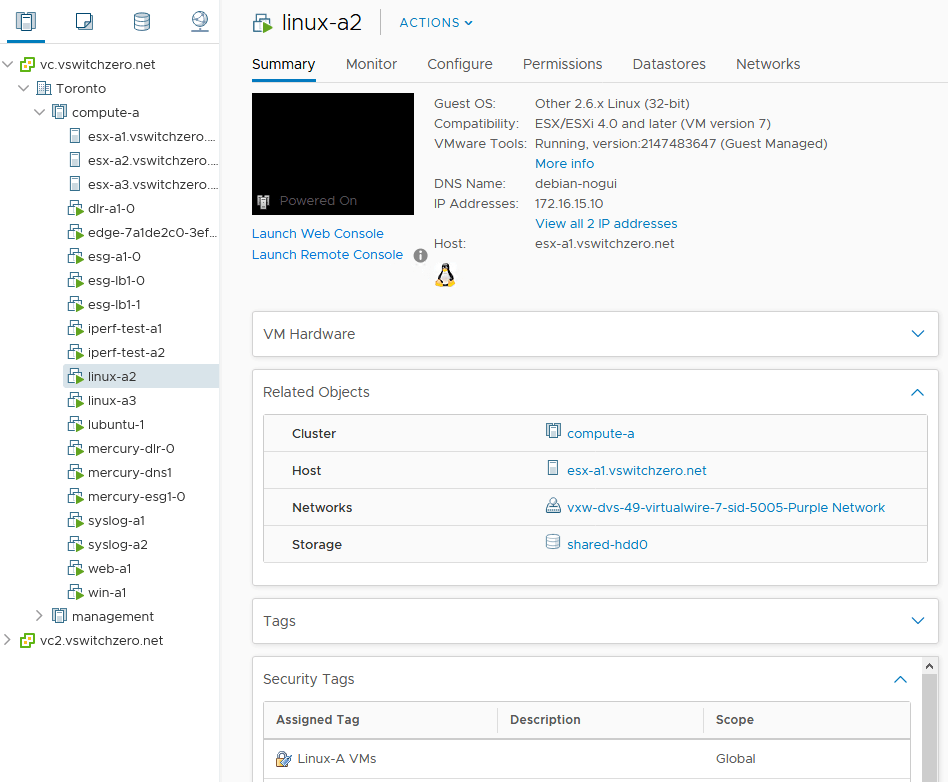
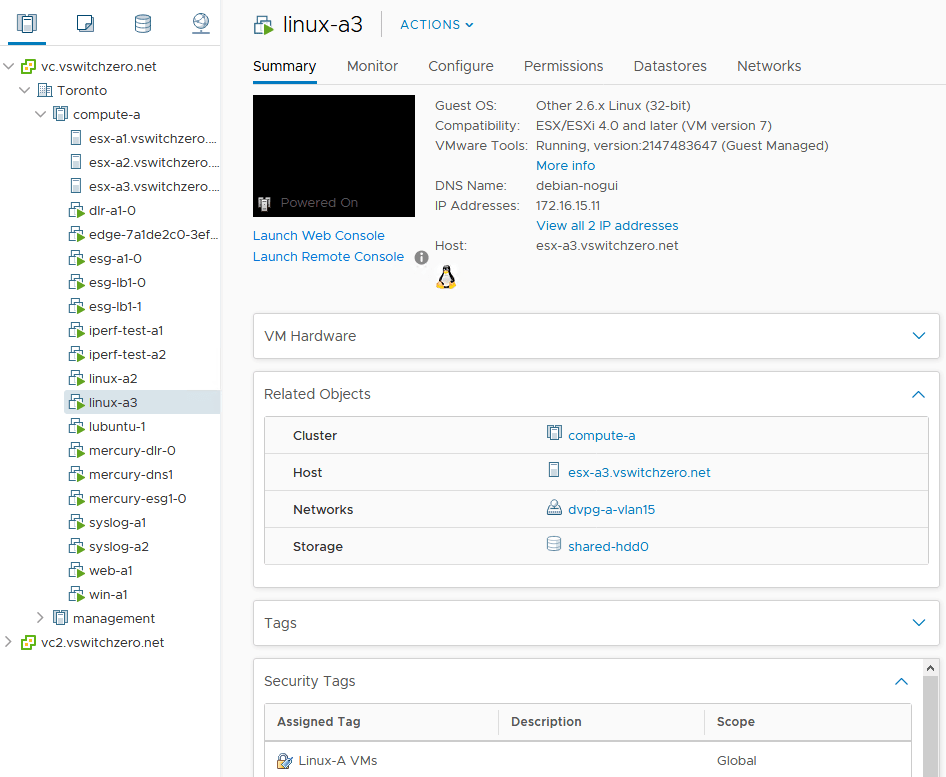
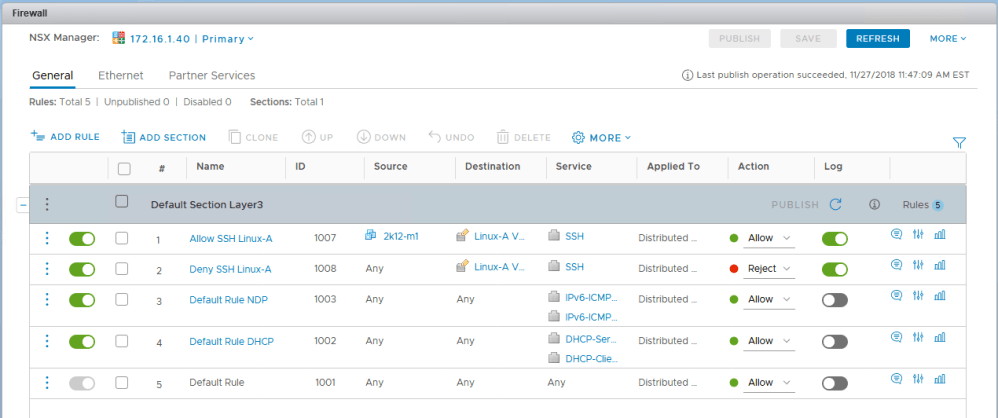
As you’ll recall in the first half, our fictional customer was getting some unexpected behavior from a couple of firewall rules. Despite the rules being properly constructed, one VM called linux-a3 continued to be accessible via SSH.
We confirmed that the IP addresses for the machines in the security group where translated correctly by NSX and that the ruleset didn’t appear to be the problem. Let’s recap what we know:
- VM linux-a2 seems to be working correctly and SSH traffic is blocked.
- VM linux-a3 doesn’t seem to respect rule 1007 for some reason and remains accessible via SSH from everywhere.
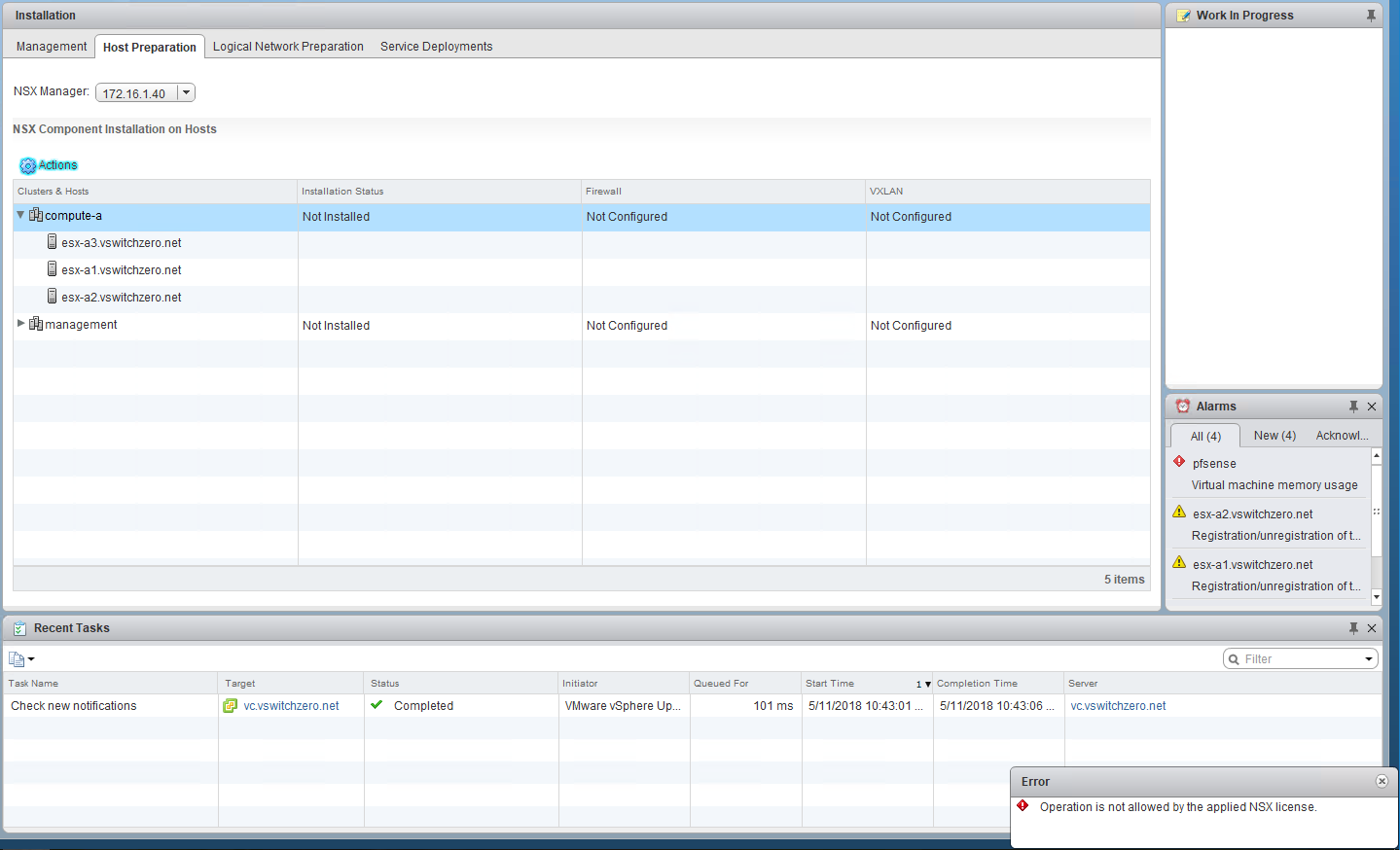
- Host esx-a3 where linux-a3 resides doesn’t appear to log any activity for rule 1007 or 1008 even though those rules are configured to log.
- The two VMs are on different ESXi hosts (esx-a1 and esx-a3).
- VMs linux-a2 and linux-a3 are in different dvPortgroups.
Given these statements, there are several things I’d want to check:
- How can the two VMs have proper IP connectivity in VXLAN and VLAN porgroups as observed?
- Is the DFW working at all on host esx-a3?
- Did the last rule publication make it to host esx-a3 and does it match what we see in the UI?
- Is the DFW (slot-2) dvfilter applied to linux-a3 correctly?
Continue reading “NSX Troubleshooting Scenario 12 – Solution”