As you may have noticed in my recent Building a Retro Gaming Rig series, I’m quite passionate about 1990s era PC hardware. Machines from this time are very nostalgic to me as this is when I really started getting interested in PCs and technology in general. Granted, PC gaming is what really drove my interest in hardware initially, but down the line, I really started enjoyed the hardware just for the sake of it.
I’ve only recently started acquiring and collecting vintage hardware in the last year or so, but I’ve always been drawn to 486 systems. Although we had an old monochrome 8-bit machine growing up – some kind of XT clone – the first PC I was really interested in was a 486 system bought in 1994.
This won’t be the first 486 system I have in my collection. I got a well maintained DEC low profile system from my brother-in-law last summer. It’s a nice system that I hope to take a look at in another post, but it’s very integrated. Everything is on-board and proprietary so it leaves very little room for tweaking. That said, I really wanted something I could customize.
Today’s project all started with an ad on Kijiji I stumbled on a few weeks back – a 486 tower system in “working condition”. Inspecting the posted images carefully, I could see that the system was far from complete – it was missing a video card and didn’t have a hard drive.
Welcome to the fourth installment of a new series of NSX troubleshooting scenarios. Thanks to everyone who took the time to comment on the first half of scenario four. Today I’ll be performing some troubleshooting and will resolve the issue.
Please see the first half for more detail on the problem symptoms and some scoping.
Getting Started
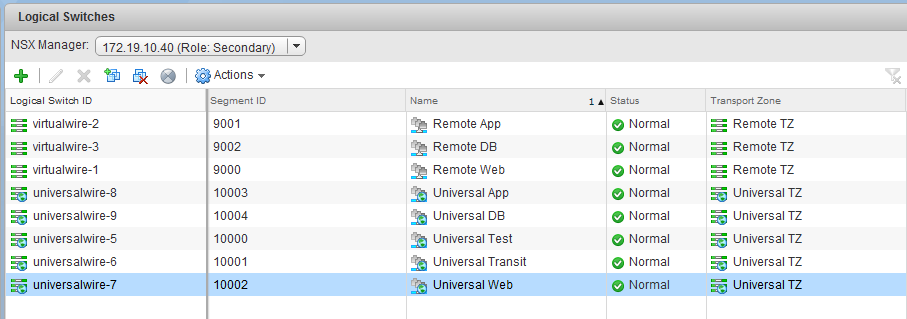
During the scoping in the first half of the scenario, we saw that the problem was squarely in the customer’s new secondary NSX deployment. Two test virtual machines – linux-r1 and linux-r2 – could not be added to any of the universal logical switches.
From the ‘Logical Switches’ view in the NSX Web Client UI, we could see that these universal logical switches were synchronized across both NSX Managers. These existed from the perspective of the Primary and Secondary manager views:
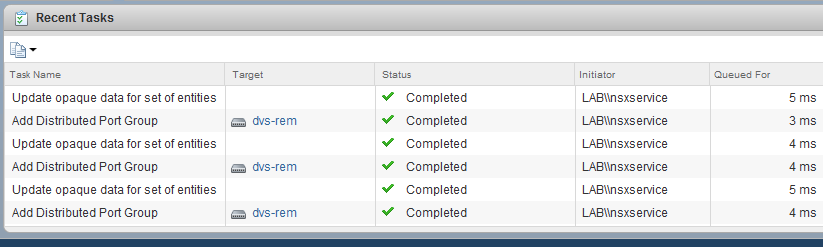
Perhaps the most telling observation, however, was the absence of distributed port groups associated with the universal logical switches on the dvs-rem switch:
As we can see above, the port groups do exist for logical switches in the VNI 900x range. These are non-universal, logical switches available to the secondary NSX deployment only.
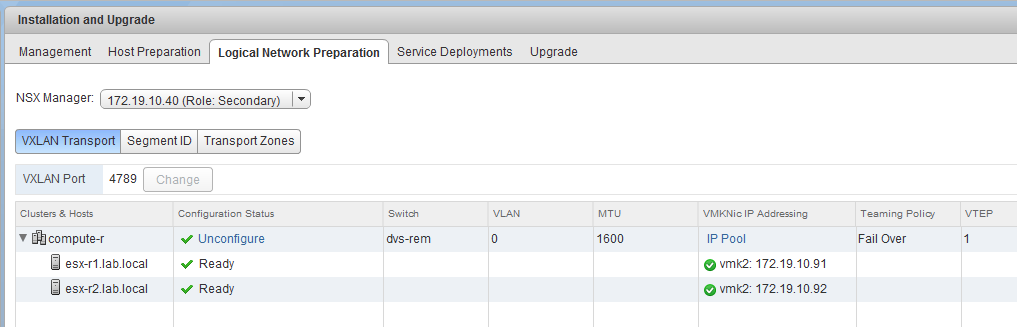
In the host preparation section, we can see that dvs-rem is indeed the configured distributed switch for the compute-r cluster and that both hosts look good from a VTEP/VXLAN perspective:
So why are these port groups missing? Without them, VMs simply can’t be added to the associated logical switches.
The Solution
Although you’ve probably noticed that I like to dig deep in some of these scenarios, this one is actually pretty straight forward. A straight forward, but all too common problem – the cluster has not been added to the universal transport zone.
You’d be surprised how often I see this, but to be fair, it’s very easily overlooked. I sometimes need to remind myself to check all the basics first, especially when dealing with new deployments. The key symptom that raised red flags for me was the lack of auto-generated port groups on the distributed switch. The addition of the cluster to the transport zone will trigger the creation of these port groups. If they don’t exist, this should be the first thing that is checked.
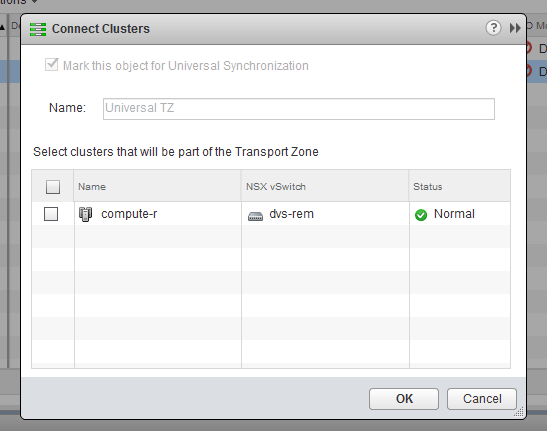
As soon as I added the compute-r cluster to the Universal TZ transport zone, we see an immediate slew of portgroup creation tasks:
I’ve now essentially told NSX that I want all the logical switches in that transport zone to span to the compute-r cluster. In NSX-V, we can think of a transport zone as a boundary spanning one or more clusters. Only clusters in that transport zone will have the logical switches available to them for use.
The concept of a ‘Universal Transport Zone’ just takes this a step further and allows clusters in different vCenter instances to connect to the same universal logical switches. The fact that we saw portgroups for the 9000-900X range of VNIs tells us that the compute-r cluster existed in the non-universal Transport Zone called ‘Remote TZ’, but was missing from ‘Universal TZ’.
Conclusion
Thanks again to everyone for posting their testing suggestions and theories! I hope you enjoyed this scenario. If you have other suggestions for troubleshooting scenarios you’d like to see, please leave a comment, or reach out to me on Twitter (@vswitchzero).
Time for another NSX troubleshooting scenario! Welcome to the fourth installment of my new NSX troubleshooting series. What I hope to do in these posts is share some of the common issues I run across from day to day. Each scenario will be a two-part post. The first will be an outline of the symptoms and problem statement along with bits of information from the environment. The second will be the solution, including the troubleshooting and investigation I did to get there.
NSX Troubleshooting Scenario 4
As always, we’ll start with a customer problem statement:
“We recently deployed Cross-vCenter NSX for a remote datacenter location. When we try to add VMs to the universal logical switches, there are no VM vNICs in the list to add. This works fine at the primary datacenter.”
This customer’s environment will be the same as what we outlined in scenario 3. Keep in mind that this should be treated separately. Forget everything from the previous scenario.
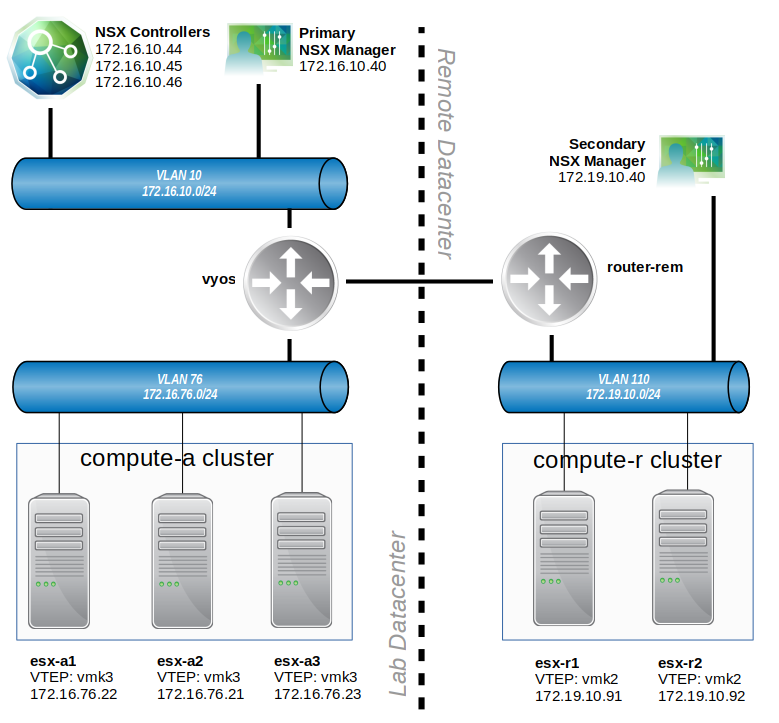
The main location is depicted on the left. A three host cluster called compute-a exists there. All of the VLAN backed networks route through a router called vyos. The Universal Control Cluster exists at this location, as does the primary NSX manager.
The ‘remote datacenter’ is to the right of the dashed line. The single ‘compute-r’ cluster there is associated with the secondary NSX manager at that location. According to the customer, this was only recently added.
Thanks to everyone who took the time to comment on the first half of scenario 3, both here and on twitter. There were many great suggestions, and some were spot-on!
For more detail on the problem, some diagrams and other scoping information, be sure to check out the first half of scenario 3.
Getting Started
During the initial scoping in the first half, we didn’t really see too much out of the ordinary in the UI aside from some odd ‘red alarm’ exclamation marks on the compute-r hosts in the Host Preparation section.
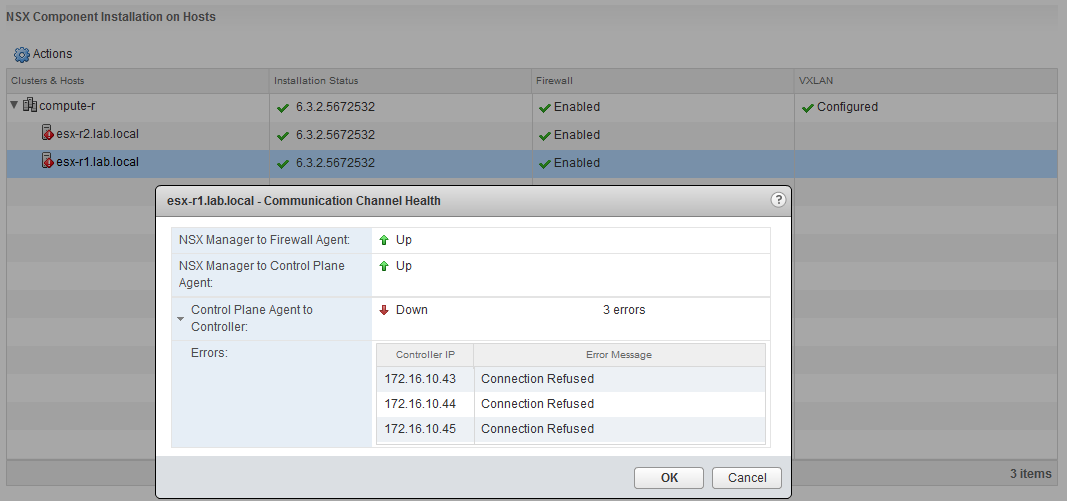
More than one commenter pointed out that this needs to be investigated. I wholeheartedly agree. Despite seeing a green status for host VIB installation, firewall status and VXLAN, there is clearly still a problem. That problem is related to ‘Communication Channel Health’.
The communication channel health check was a new feature added in NSX 6.2 and makes it easy to see which hosts are having problems communicating with both NSX Manager and the Control Cluster. In our case, both esx-r1 and esx-r2 are reporting problems with their control plane agent (netcpa) to all three controllers.
Welcome to the third installment of my new NSX troubleshooting series. What I hope to do in these posts is share some of the common issues I run across from day to day. Each scenario will be a two-part post. The first will be an outline of the symptoms and problem statement along with bits of information from the environment. The second will be the solution, including the troubleshooting and investigation I did to get there.
NSX Troubleshooting Scenario 3
I’ll start off again with a brief customer problem description:
“We’ve recently deployed Cross-vCenter NSX for a remote datacenter location. All of the VMs at that location don’t have connectivity. They can’t ping their gateway, nor can they ping VMs on other hosts. Only VMs on the same host can ping each other.”
This is a pretty vague description of the problem, so let’s have a closer look at this environment. To begin, let’s look at the high-level physical interconnection between datacenters in the following diagram:
There isn’t a lot of detail above, but it helps to give us some talking points. The main location is depicted on the left. A three host cluster called compute-a exists there. All of the VLAN backed networks route through a router called vyos. The Universal Control Cluster exists at this location, as does the primary NSX manager.
As you’ve probably noticed, VMware is regularly releasing new NSX versions and updates to introduce new features and to improve stability and scalability. Eventually, you’ll find yourself in a situation where you’ll either want or need to upgrade. Maybe you want to take advantage of some new features, encountered a problem or your version isn’t supported any more. Whatever the reason, and whatever the version, here are ten tips that will help to ensure your upgrade is successful!
Tip 1 – Check The Compatibility Matrix
Before getting started, you’ll want to thoroughly check the compatibility of your target NSX version. That doesn’t just mean checking if you can upgrade from version X to version Y, but rather to check everything that interacts with NSX in the environment.
Start with the NSX Upgrade Path found at the VMware Interoperability Matrices page. There you may be surprised to find that there are several versions of NSX that are not a feasible upgrade path. For example, you can’t upgrade from NSX 6.2.8 to 6.3.2, nor can you upgrade from 6.2.6 to 6.3.1.
Taken from the NSX Upgrade Path on VMware’s website.
Once you’ve confirmed that your target version is supported in the upgrade path, you’ll want to look at the Interoperability Matrix to ensure products like vSphere and Cloud Director are compatible. Again, there are several incompatible releases that you may not expect. For example, NSX 6.3.3 and later releases aren’t compatible with vCenter Server 6.0 U1 and older, but are compatible with all releases of 5.5. Another example is the initial release of vSphere 6.5. Only 6.5a or later can be used with any version of NSX 6.3.x.
If you are new to NSX or looking to evaluate it in the lab, there is one very common issue that you may run into. After going through the initial steps of deploying and registering NSX Manager with vCenter, you may be surprised to find that there are no manageable NSX managers listed under ‘Networking and Security’ in the Web Client. Although the registration and Web Client plugin installation appears successful, there is often an extra step needed before you can manage things.
One of the first tasks involved in deploying NSX is to register NSX Manager with a vCenter Server. This is done for inventory management and synchronization purposes. The NSX Manager can be optionally registered with SSO as well.
In my lab, I’ve used the SSO administrator account for registration.
The vCenter user that is used for registration needs to have the highest level of privileges for NSX to work correctly. The NSX install guide clearly states that this must be the vCenter ‘Administrator’ role.
From the NSX Install Guide:
“You must have a vCenter Server user account with the Administrator role to synchronize NSX Manager with the vCenter Server. If your vCenter password has non-ASCII characters, you must change it before synchronizing the NSX Manager with the vCenter Server.”
Because of these requirements, it’s quite common to use the SSO administrator account – usually administrator@vsphere.local. A service account is also often created for this purpose to more easily identify and distinguish NSX tasks. Either way, these are not normally accounts that you’d use for day-to-day administration in vSphere.
By default, NSX will only assign its ‘Enterprise Administrator’ role to the user account that was used to register it with vCenter Server. This means that by default, only that specific vCenter user will have access to the NSX manager from within the Web Client.
That said, if you are experiencing this problem, you are probably not logged in with the vCenter user that was used for registration purposes. To grant access to other users, you’ll need to log into the vSphere Web Client using the registration user account, and then add additional users and groups.
In my lab, I’ve just logged in with an active directory user called ‘test@lab.local’. This user has full administrator privileges in vCenter, but has no access to any NSX Managers:
No managers to manage!
If I log out, and log back in with the administrator@vsphere.local account that was used for vCenter registration, I can see the NSX managers that were registered.
In my lab, I’ve got a secondary deployed as well, but we’ll focus only on 172.16.10.40. If I click on that manager in the list, I’m able to go to the ‘Users’ tab to see what the default permissions look like:
As you can see, only one user – the SSO administrator account used for registration – has the requisite role for administrator via the Web Client. In my lab, I want to provide full access to an AD group called ‘VMware Admins’ and an individual user called ‘Test’.
Both vCenter users and groups can be specified here. As long as vCenter can authenticate them – either via SSO, local authentication or even AD – they are fair game.
Another common mistake made is selecting the NSX Administrator role rather than Enterprise Administrator. NSX Administrator sounds like the highest privilege level, but it’s actually Enterprise Administrator that gives you all the keys to the kingdom. You won’t be able to administer certain things – including user permissions – unless Enterprise Administrator is chosen.
Once this is done, you’ll see the users and groups listed and should now have the correct permissions to administer the NSX deployment!
Keep in mind that if you’ve got more than one NSX manager deployed, you’ll need to set this on each independently.
Have any questions or want more information? Please feel free to leave a comment below or reach out to me on Twitter (@vswitchzero)
ARP suppression is one of the key fundamental features in NSX that helps to make the product scalable. By intercepting ARP requests from VMs before they are broadcast out on a logical switch, the hypervisor can do a simple ARP lookup in its own cache or on the NSX control cluster. If an ARP entry exists on the host or control cluster, the hypervisor can respond directly, avoiding a costly broadcast that would likely need to be replicated to many hosts.
ARP Suppression has existed in NSX since the beginning, but it was only available for VMs connected to logical switches. Up until NSX 6.2.4, the DLR kernel module did not benefit from ARP suppression and every non-cached entry needed to be broadcast out. Unfortunately, the DLR – like most routers – needs to ARP frequently. This can be especially true due to the easy L3 separation that NSX allows using logical switches and efficient east-west DLR routing.
Despite having code in the 6.2.4 and later version DLRs to take advantage of ARP suppression, a large number of deployments are likely not actually taking advantage of this feature due to a recently identified problem.
VMware KB 51709 briefly describes this issue, and makes note of the following conditions:
“DLR ARP Suppression may not be effective under some conditions which can result in a larger volume of ARP traffic than expected. ARP traffic sent by a DLR will not be suppressed if an ESXi host has more than one active port connected to the destination VNI, for example the DLR port and one or more VM vNICs.”
What isn’t clear in the KB article, but can be inferred based on the solution is that the problem is related to VLAN tagging on logical switch dvPortgroups. Any dvPortgroup associated with a logical switch with a VLAN ID specified is impacted by this problem.
It’s been a while since my last retro build post, but the build is finally complete! Actually, it’s been done for several weeks, but I just haven’t have time to break out the camera and get some pictures.
Without further ado, let’s have a look at the finishing touches and the final build!
Completed Build
For the case, I decided to use an old Antec NSK 3480 that I had lying around. I love the very simple appearance, but most of all, the small dimensions. With a depth of only 14 inches, it’s only as deep as it is tall. This can make for some challenges, but also makes it a perfect fit for slim boards.
Although it really doesn’t look like a retro box, I like that it’s very unassuming and feels a lot like a ‘sleeper’ build. I’ve got an old Pentium 90 and yellowed 486 rig that I’ll save for that true old-school appearance!
The Antec case was perfect for the MSI MS-6160 board. It even left enough space at the front of the case for the IDE-to-SD adapter board. For more detail on the motherboard, check out Part 3 of the series.
Welcome to the second installment of a new series of NSX troubleshooting scenarios. This is the second half of scenario two, where I’ll perform some troubleshooting and resolve the problem.
Please see the first half for more detail on the problem symptoms and some scoping.
Getting Started
As mentioned in the first half, the problem is limited to a host called esx-a1. As soon as a guest moves to that host, it has no network connectivity. If we move a guest off of the host, its connectivity is restored.
We have one VM called win-a1 on host esx-a1 for testing purposes at the moment. As expected, the VM can’t be reached.
To begin, let’s have a look at the host from the CLI to figure out what’s going on. We know that the UI is reporting that it’s not prepared and that it doesn’t have any VTEPs created. In reality, we know a VTEP exists but let’s confirm.
To begin, we’ll check to see if any of the VIBs are installed on this host. With NSX 6.3.x, we expect to see two VIBs listed – esx-vsip and esx-vxlan.