Ever remove a cluster from your NSX transport zone only to see it reappear on the list of clusters available for disconnection? Unfortunately, the task likely failed but NSX doesn’t always do a very good job of telling you why in the UI.
I was recently attempting to remove a cluster called compute-b from my transport zone so that I could remove and rebuild the hosts within. Needless to say, I ran into some difficulties and wanted to share my experience.
If you are interested in some more detailed instructions on how to decommission NSX prepared hosts, you can check out my post on Completely Removing NSX. From a high level, the steps I wanted to do were the following:
- Disconnect all VMs from logical switches in the cluster to be removed.
- Remove the cluster from the transport zone. This will remove all port groups associated with the logical switches (assuming no other clusters are connected to the same distributed switch)
- ‘Unconfigure’ VXLAN from the ‘Logical Network Preparation’ tab to remove all VTEPs.
- Uninstall the NSX VIBs from the Host Preparation Tab.
To begin, I used the ‘Remove VM’ button from the Logical Switches view in NSX. I removed all four of the VMs attached to the only Logical Switch being used at the moment. I saw a bunch of VM reconfigure tasks complete, and assumed it had completed successfully.
I then went to disconnect compute-b from the transport zone called Primary TZ. After removing the cluster and clicking OK, the dialog closed giving the impression that the task was successful. Oddly though, I didn’t see the tasks related to port group removal that I expected to see.
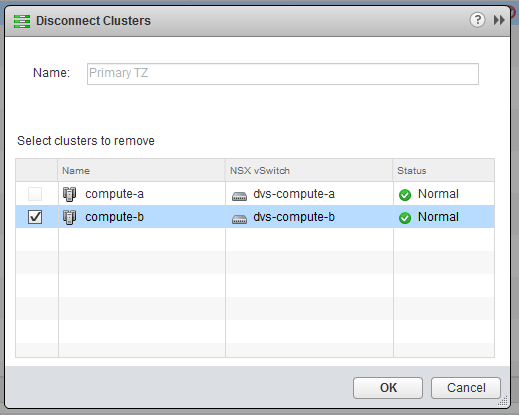
Sure enough, I went back into the ‘Disconnect Clusters’ dialog and saw the compute-b cluster still in the list. Unfortunately, NSX doesn’t appear to report failures for this particular workflow in the UI.
Having worked in support for many years, I followed my first instinct and checked the NSX Manager vsm.log file for detail on why the operation failed. I received the below failure details:
2017-11-24 18:50:13.016 GMT+00:00 INFO taskScheduler-8 JobWorker:243 - Updating the status for jobinstance-101742 to EXECUTING
2017-11-24 18:50:13.022 GMT+00:00 INFO taskScheduler-8 SchedulerQueueServiceImpl:64 - [TF] Created a new bucket for module default_module and total number of buckets 1
2017-11-24 18:50:13.022 GMT+00:00 INFO taskScheduler-8 SchedulerQueueServiceImpl:80 - The task ShrinkVdnScope-vdnscope-1 (1511549412299) [id:task-102755] is added to the SchedulerQueue
2017-11-24 18:50:13.022 GMT+00:00 INFO pool-10-thread-1 ScheduleSynchronizer:48 - Start executing task: task-102755 and running executor threads 1
2017-11-24 18:50:13.042 GMT+00:00 INFO TaskFrameworkExecutor-3 VdnScopeServiceImpl$2:995 - New VDS (count: 1) is being removed when shrinking scope vdnscope-1. Shrinkingwires.
2017-11-24 18:50:13.061 GMT+00:00 ERROR TaskFrameworkExecutor-3 VirtualWireServiceImpl:1577 - validation failed at delete backing for dvportgroup-815 in the scope: vdnscope-1
2017-11-24 18:50:13.061 GMT+00:00 ERROR TaskFrameworkExecutor-3 VdnScopeServiceImpl$2:1015 - Shrink operation failed on TZ vdnscope-1
2017-11-24 18:50:13.061 GMT+00:00 ERROR TaskFrameworkExecutor-3 Worker:219 - BaseException thrown while executing task instance taskinstance-166334
com.vmware.vshield.vsm.vdn.exceptions.XvsException: core-services:819:Transport zone vdnscope-1 contraction error.
at com.vmware.vshield.vsm.vdn.service.VirtualWireServiceImpl.validateShrink(VirtualWireServiceImpl.java:1578)
at com.vmware.vshield.vsm.vdn.service.VdnScopeServiceImpl$2.doTask(VdnScopeServiceImpl.java:1001)
at com.vmware.vshield.vsm.vdn.service.task.AbstractVdnRunnableTask.run(AbstractVdnRunnableTask.java:80)
at com.vmware.vshield.vsm.task.service.Worker.runtask(Worker.java:184)
at com.vmware.vshield.vsm.task.service.Worker.executeAsync(Worker.java:122)
at com.vmware.vshield.vsm.task.service.Worker.run(Worker.java:99)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
2017-11-24 18:50:13.068 GMT+00:00 INFO TaskFrameworkExecutor-3 JobWorker:243 - Updating the status for jobinstance-101742 to FAILED
There is quite a bit there, but the key takeaways are that the task clearly failed and that the reason was: “validation failed at delete backing for dvportgroup-815 in the scope: vdnscope-1”
This doesn’t tell us why exactly, but it seems clear that the operation can’t delete dvportgroup-815 and fails. In my experience, 99% of the time this is because there is still something connected to the portgroup.
Since there were only four VMs in the cluster, and no ESGs or DLRs – I wasn’t sure what could possibly be connected. I even shut down all four disconnected VMs and put all three hosts in maintenance mode just to be sure. None of these actions helped.
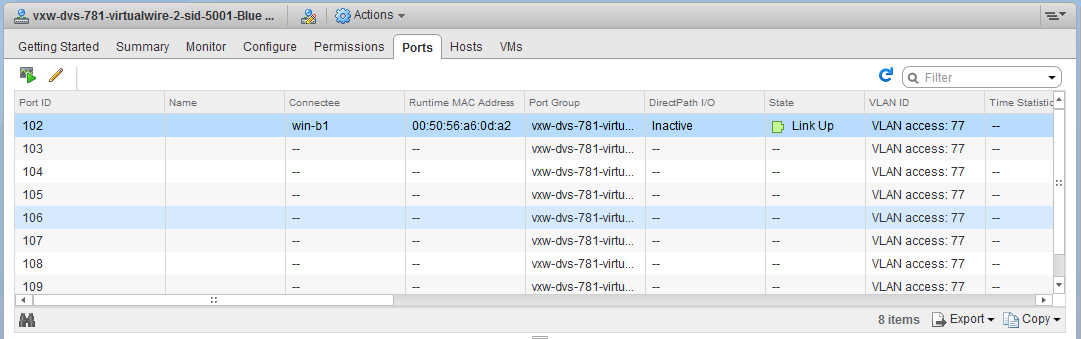
I then navigated to the Networking view in vCenter to have a look at the DVS associated with the compute-b cluster. In the ‘Ports’ view, you can get a good idea of what exactly is still connected to the distributed switch. To my surprise a VM called win-b1 was actually still showing as ‘Active’ and ‘Connected’ to the dvPortgroup associated with a Logical Switch!
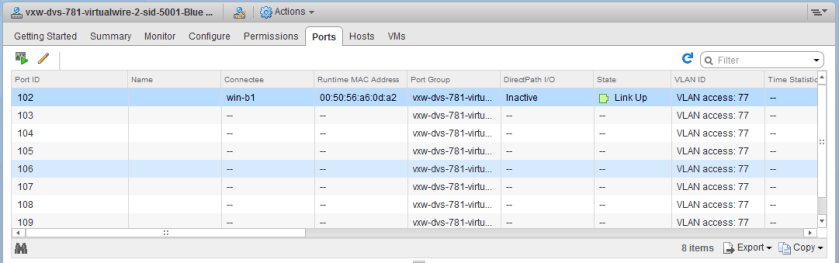
This dvPort state is clearly wrong – first of all, the VM was powered off so it could not be ‘Link Up’. Secondly I thought I had removed the VM. Or did I?
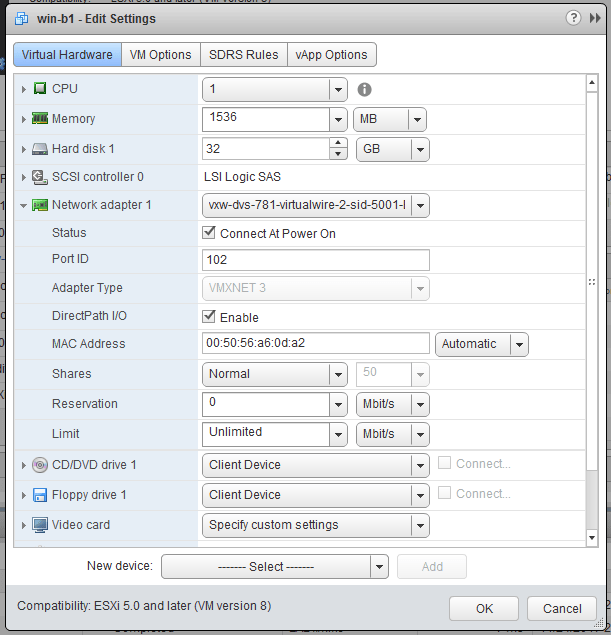
Although I didn’t see any failures, it doesn’t appear that this VM was removed from the Logical Switch. Maybe I missed it, or perhaps it was a quirk due to the bug outlined in KB 2145889 where DirectPath I/O is enabled on VMs created with the vSphere Web Client. This was the only VM that had this option checked off, but despite my best efforts I could not reproduce the problem. Regardless, knowing what the problem was, I could simply disconnect the NIC and add it to another temporary portgroup.
This adjustment appeared to refresh the DVS port state and then I was able to remove the cluster from the Transport Zone successfully.
When in doubt, don’t hesitate to dig into the NSX Manager logging. If the UI doesn’t tell you why something didn’t work or is light on details, the logging can often set you in the right direction!