Welcome to the fourteenth installment of a new series of NSX troubleshooting scenarios. Thanks to everyone who took the time to comment on the first half of the scenario. Today I’ll be performing some troubleshooting and will show how I came to the solution.
Please see the first half for more detail on the problem symptoms and some scoping.
Getting Started
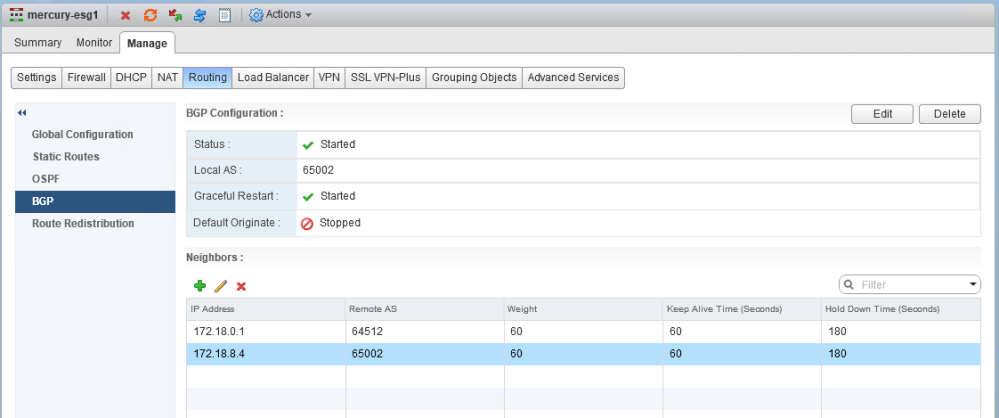
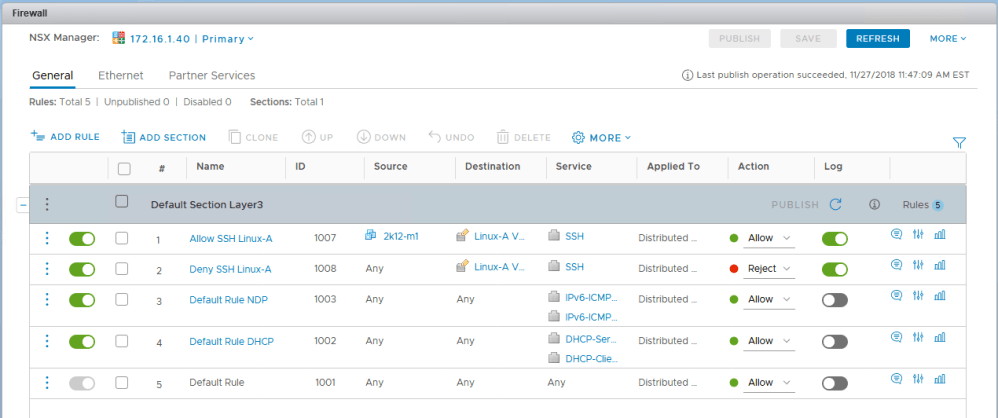
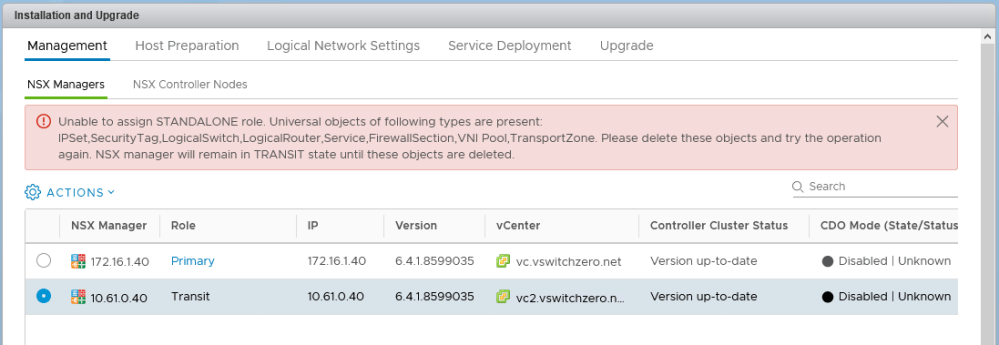
In the first half, our fictional customer was trying to prevent a specific summary route from being advertised to a DLR appliance using a BGP filter. Every time they added the filter, all connectivity to VMs downstream from that DLR was lost.
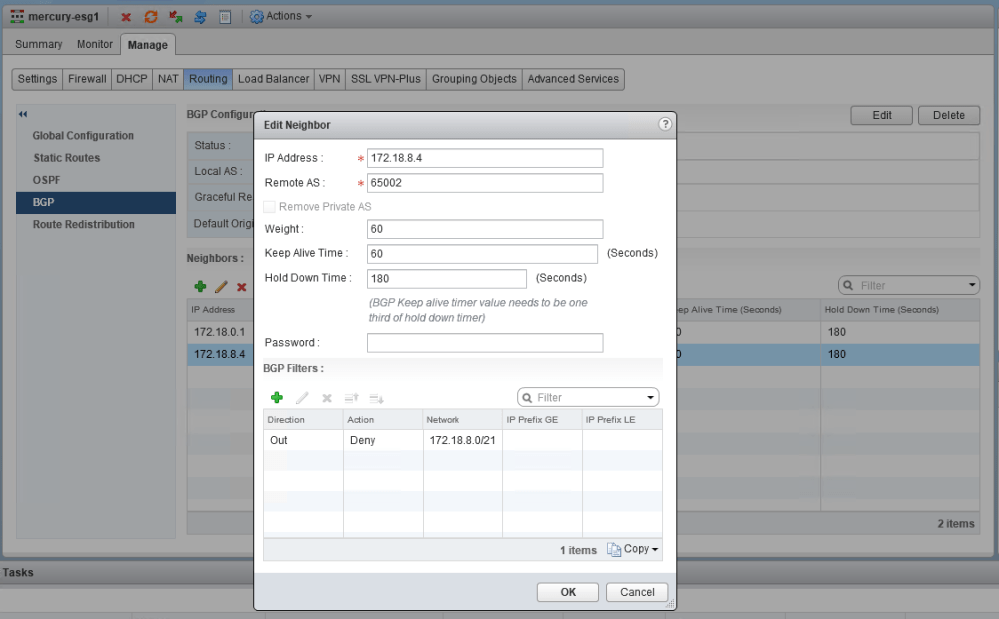
The filter appears correct. The summary route is a /21 network that comprises all eight /24s that were assigned to logical switches. You can also see that GE and LE (greater than/less than) values were not specified, so the specific summary route should be matched exactly.
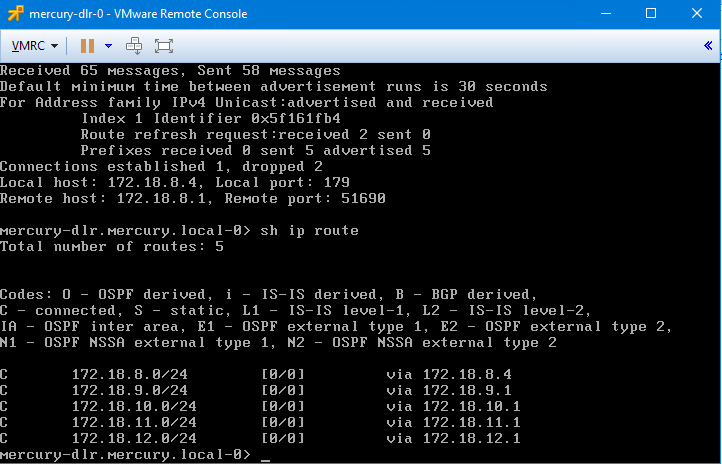
After publishing the changes, we saw that all BGP routes were removed from the DLR. It’s almost as if the filter stopped ALL route prefixes from making it to the DLR rather than just the one specified. Wait, did it?
Let’s refer to the NSX documentation on BGP filters. Under the Configure BGP section, the relevant steps are the following:
Continue reading “NSX Troubleshooting Scenario 14 – Solution”